


L’annuncio del nuovo framework per l’integrazione tra HPC e quantum computing segna un passaggio chiave nella strategia IBM: non solo sviluppo dell’hardware quantistico, ma costruzione di un’architettura in cui sistemi classici e quantum possano operare insieme in modo nativo.
È su questo terreno che Alessandro Curioni, IBM Fellow, Vice President IBM Europe and Africa e direttore dell’IBM Research Lab di Zurigo, colloca il significato della roadmap presentata: non una semplice evoluzione delle prestazioni, ma un cambio di paradigma nel modo in cui il calcolo viene progettato e applicato ai problemi concreti.
L’integrazione tra HPC e quantum, in questa prospettiva, non è un livello aggiuntivo, ma la condizione necessaria per rendere il quantum computing utilizzabile su scala. Ed è proprio da qui che si comprende il punto di partenza del suo ragionamento: il quantum non introduce solo una nuova tecnologia, ma un modo diverso di rappresentare l’informazione.
Quantum computing: una nuova rappresentazione dell’informazione
Il punto di partenza è il significato stesso di quantum computing. Alessandro Curioni chiarisce subito che non si tratta di una semplice evoluzione delle tecnologie di calcolo esistenti, ma di un cambiamento più profondo, che riguarda la rappresentazione dell’informazione. “Il quantum computing non è solamente un nuovo modo di fare computing: è parte della ridefinizione di come rappresentiamo l’informazione”.
Nel paradigma classico, l’informazione è rappresentata in forma discreta, attraverso bit che assumono valore zero o uno. Nel quantum computing, invece, la rappresentazione cambia natura. Curioni utilizza un’immagine precisa: “Possiamo rappresentare l’informazione su una sfera, dove zero e uno sono il Polo Nord e il Polo Sud, mentre tutto ciò che sta in mezzo è una continuità di stati possibili”.
Questa differenza consente di costruire algoritmi diversi, perché cambia il modo in cui i problemi vengono espressi. “Quello che riesci a fare in modo più semplice e naturale con una rappresentazione dell’informazione può essere molto difficile nell’altra, e viceversa”.
La conseguenza è che quantum e classical computing non sono alternative. “Non saranno mai due cose distinte, né due tecnologie in cui una sostituisce l’altra: devono convivere”.
Dove il quantum è più efficace (e dove no)
Il motivo emerge guardando al comportamento delle singole operazioni. “Se provo a fare tutto con un quantum computer, alcune operazioni risultano più difficili: la moltiplicazione, per esempio, è più complessa rispetto al classico”. Al contrario, “la fattorizzazione – cioè risalire ai fattori di un numero – è estremamente difficile nel classico, ma molto più semplice nel quantum”.
La differenza si riflette nella teoria della complessità. “Ci sono problemi che nel dominio classico hanno complessità esponenziale e che, se rappresentati in modo quantistico, diventano polinomiali”. Questo li rende affrontabili su scala.
Allo stesso tempo, il passaggio al quantum non è automaticamente vantaggioso. “Se un problema viene rappresentato male in quantum, diventa molto complesso. In questi casi non ha senso eseguirlo su un quantum computer, anche se sarebbe possibile”.
Ne deriva un modello in cui la scelta della tecnologia dipende dalla natura del problema e dalla sua rappresentazione. “Non ha senso pensare a un computing completamente quantistico. Serve una combinazione dei due”.
La macchina non basta: il limite del quantum isolato
La roadmap IBM verso sistemi quantistici fault tolerant è definita con precisione: l’obiettivo è arrivare entro il 2029 a piattaforme con centinaia di qubit e centinaia di milioni di operazioni al secondo.
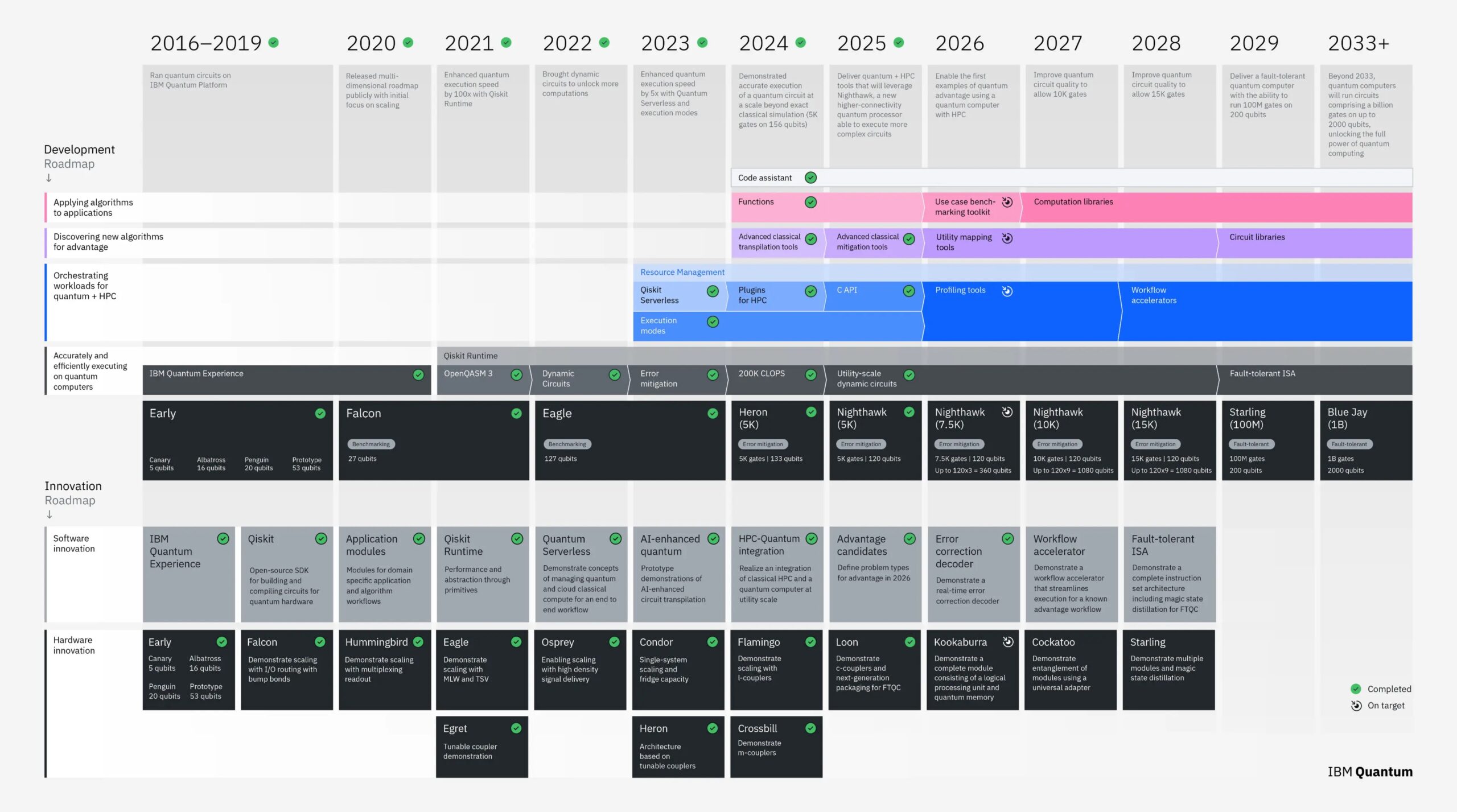
Ma Curioni chiarisce subito che questo traguardo, preso da solo, non risolve il problema.
“Noi abbiamo una roadmap molto chiara che ci porta al 2029 ad avere un quantum computer fault-tolerant, con centinaia di qubit e centinaia di milioni di operazioni al secondo. Ma fare solo quello non è abbastanza”.
Il limite non è nella tecnologia del quantum in sé, ma nella sua applicabilità. La questione diventa operativa nel momento in cui si passa dalla dimostrazione scientifica all’utilizzo su problemi reali. “Se voglio applicare questo tipo di computing a problemi veri – sia di scienza sia di business – devo integrare il quantum computer con il miglior classical computing disponibile”.
L’approccio tradizionale: possibile, ma inefficiente
Un modello di integrazione esiste già, ma non è sostenibile su scala. “Posso prendere i dati, fare una parte del calcolo sul classico, portarli sul quantum, eseguire il quantum e poi riportare i risultati indietro”.
Curioni non lo esclude, ma ne evidenzia il limite: “È possibile, ma non è efficiente”. Il problema è strutturale. Ogni passaggio tra ambienti diversi introduce latenza, richiede conversioni di formato, duplicazioni di controllo e gestione separata dei flussi di dati. Il risultato è un sistema frammentato, in cui l’integrazione è affidata a orchestrazioni manuali o semi-manuali.
Il framework: integrazione nativa tra HPC e quantum
Per superare questo limite, IBM introduce un modello diverso, basato sull’integrazione diretta. “Abbiamo creato un framework che mette insieme le due architetture – HPC e quantum – includendo linguaggi, controlli, dataflow e middleware, come Qiskit, in modo da rendere più semplice lo sviluppo e l’esecuzione delle applicazioni”.
L’obiettivo è eliminare la separazione tra i due ambienti, costruendo un’infrastruttura in cui classical e quantum possano essere utilizzati in modo continuo, senza passaggi espliciti e senza dover ricostruire ogni volta il collegamento tra i due. Questo implica un’integrazione a più livelli, dai linguaggi di programmazione ai sistemi di controllo alla gestione dei dati e dei flussi e al middleware. Il risultato è una piattaforma in cui il problema viene distribuito automaticamente tra le due modalità di computing, senza che lo sviluppatore debba gestire direttamente la separazione.
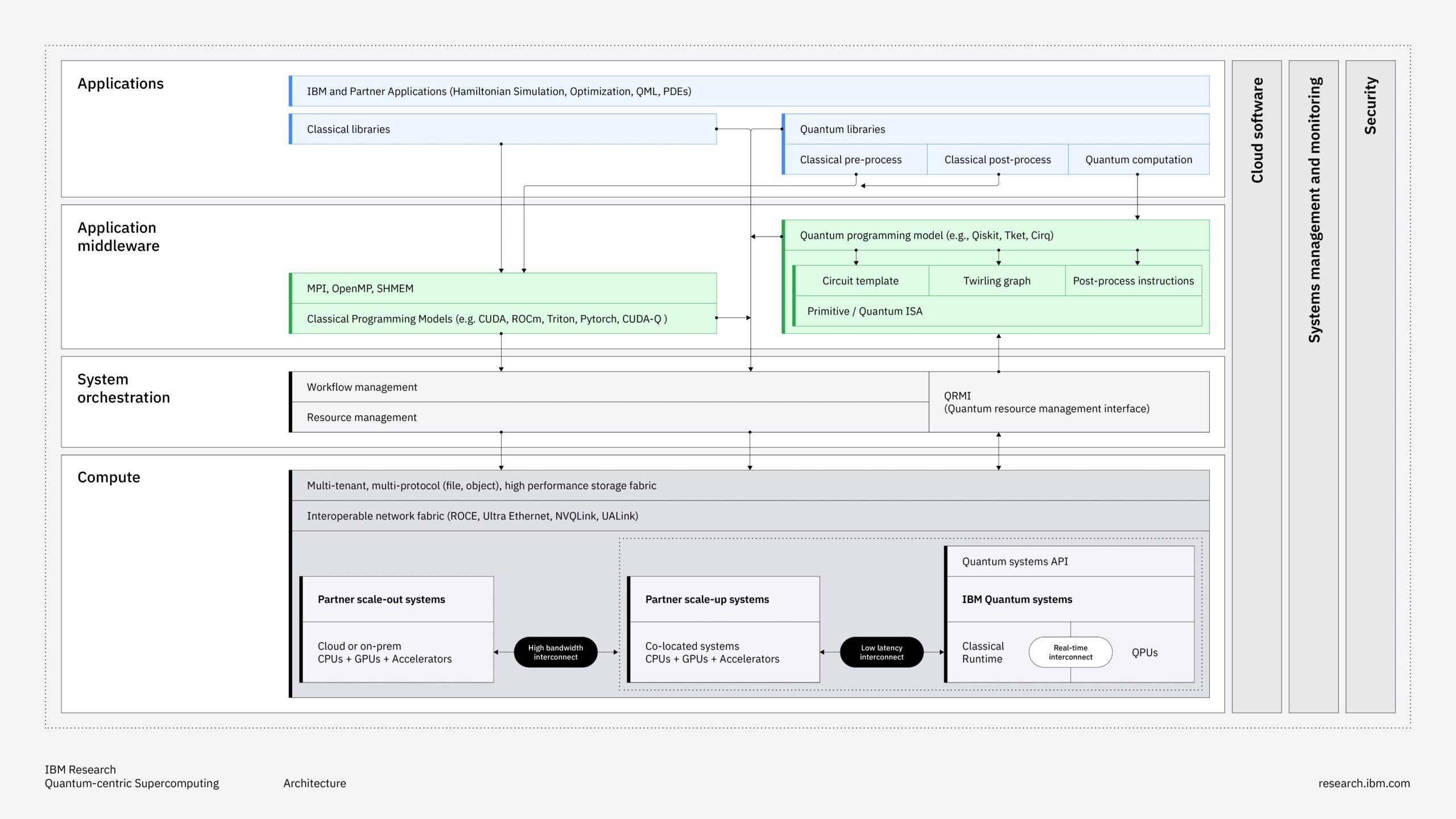
Il framework non è pensato come una soluzione definitiva, ma come un elemento in evoluzione: “non esiste solo una roadmap del quantum computing: serve anche una roadmap dell’integrazione”.
Le capacità disponibili oggi – basate su sistemi error mitigated – sono molto diverse da quelle future, quando sarà possibile operare con error correction su larga scala. Questo implica che anche le modalità di integrazione devono cambiare. Il punto è che l’integrazione non è un accessorio del sistema, ma parte della sua architettura.
Dal software all’hardware: l’evoluzione dell’integrazione
Nel breve termine, l’integrazione è prevalentemente software. “Oggi è principalmente a livello software, ma in futuro sarà anche a livello hardware”. Questo significa che classical e quantum computing non saranno solo collegati logicamente, ma diventeranno sempre più vicini anche fisicamente, con una convergenza progressiva dei livelli di controllo.
Man mano che la scala dei sistemi cresce – passando da decine a centinaia e poi migliaia di qubit – aumentano anche le esigenze di coordinamento tra le componenti. Il risultato è una progressiva omogeneizzazione dei meccanismi di gestione e orchestrazione.
La roadmap, quindi, non riguarda solo il numero di qubit o le prestazioni del processore quantistico, bensì la capacità di costruire un ambiente in cui classical e quantum possano operare insieme in modo continuo, senza frizioni. Il punto non è più collegare due sistemi, ma costruire un unico spazio computazionale in cui ogni parte del problema venga eseguita nel dominio più adatto.
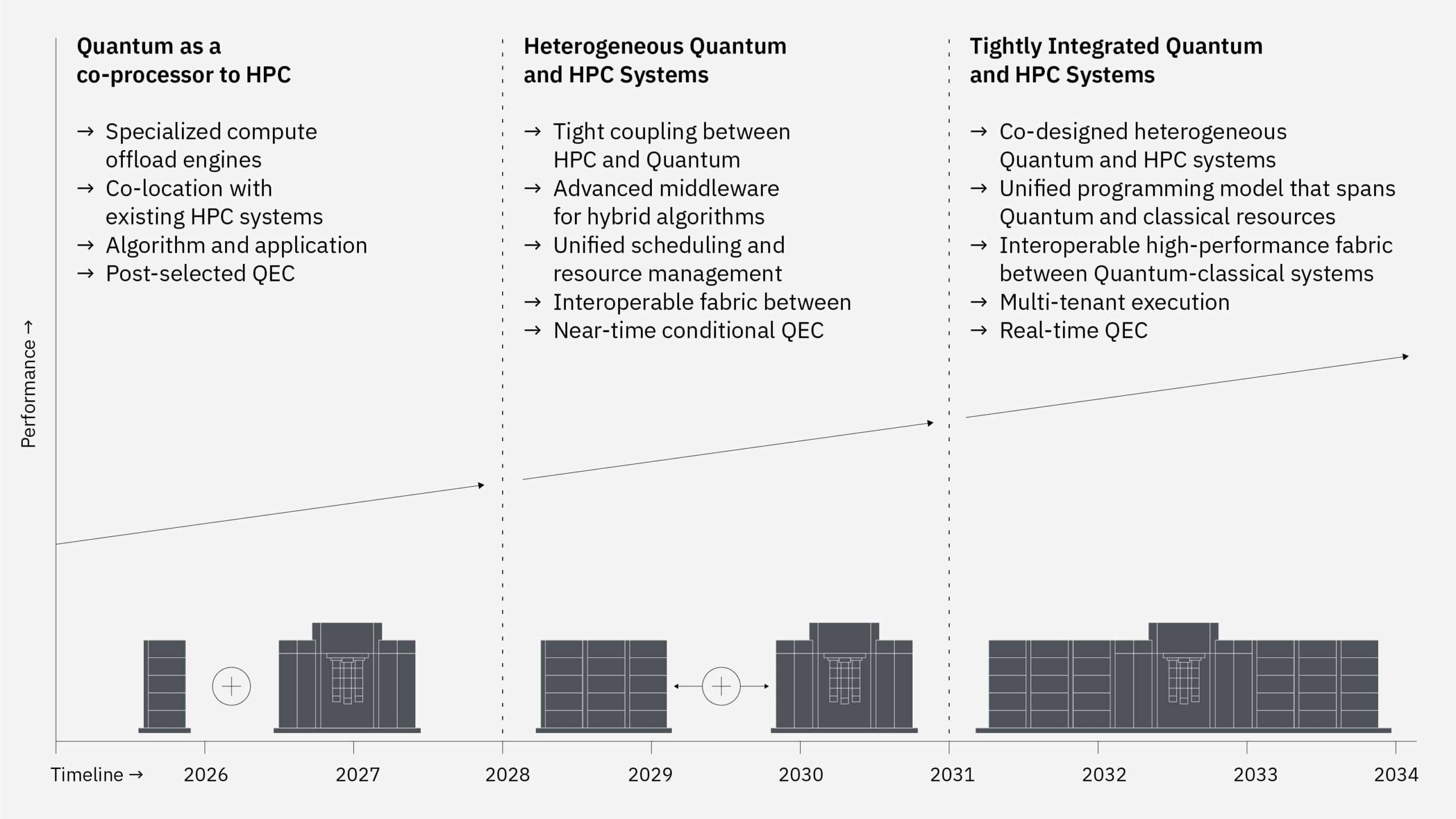
Quantum-centric supercomputing: il cambio di centro del sistema
Il nome del framework – quantum-centric supercomputing – indica un cambiamento nel modo in cui viene progettata l’intera architettura di calcolo.
Per chiarire il significato di “quantum-centric”, Curioni ricostruisce l’evoluzione del computing negli ultimi decenni. In passato, il centro del sistema era la CPU: “Trent’anni fa eravamo in un mondo CPU-centric; tutto era disegnato intorno alla CPU”. Questo significava che memoria, cache e interconnessioni erano progettate con un unico obiettivo: evitare colli di bottiglia verso il processore principale.
Con l’avvento dell’intelligenza artificiale e del deep learning, questo equilibrio si è spostato. “Siamo diventati GPU-centric”, osserva Curioni, sottolineando che oggi anche sistemi non specialistici sono progettati attorno alla GPU. Non è più la CPU il punto di massima criticità, ma l’unità che esegue i carichi computazionali più intensivi, soprattutto in ambito AI.
Il passaggio successivo è quello che porta al quantum. “Quando arriviamo nel quantum, sarà la parte a maggior valore, la più differenziante; e tutto il resto sarà disegnato per non avere colli di bottiglia rispetto a quella parte”.
La logica è la stessa delle fasi precedenti, ma applicata a una tecnologia diversa. CPU, GPU e storage non scompaiono, ma vengono riposizionati all’interno dell’architettura. Non sono più il centro, ma elementi che devono alimentare il componente più critico: il processore quantistico.
Questo implica una progettazione dell’intero sistema – dalle interconnessioni alla gestione dei dati – orientata a massimizzare l’utilizzo del quantum, evitando che resti inutilizzato a causa di limiti nelle altre componenti.
Il parallelismo con i data center: il ruolo delle interconnessioni
Curioni richiama esplicitamente ciò che è già avvenuto nei data center. “Lo sviluppo di tecnologie come NVLink è fatto per un motivo molto semplice: permettere di utilizzare la GPU al massimo delle sue capacità”.
Non si tratta di un miglioramento accessorio, ma di una conseguenza diretta del cambio di centralità. Quando un componente diventa il collo di bottiglia del sistema, tutto il resto viene progettato per servirlo nel modo più efficiente possibile.
Nel quantum accadrà lo stesso. Le scelte architetturali – dalle connessioni tra nodi alla gestione della memoria e dei flussi di dati – saranno guidate dalla necessità di sfruttare al massimo il processore quantistico.
Il parallelismo con GPU e acceleratori ha però un limite preciso. “GPU e coprocessori accelerano lo stesso tipo di computing”, osserva Curioni. “Qui, invece, abbiamo due rappresentazioni dell’informazione che sono diverse”.
Questo significa che il quantum non è un acceleratore nel senso tradizionale. Non rende più veloce lo stesso tipo di operazioni, ma introduce un modo diverso di esprimere i problemi. La differenza non è quindi solo ingegneristica, ma teorica.
Dalla fisica all’information theory
Per spiegare questo passaggio, Curioni richiama un parallelo con la fisica. All’inizio del Novecento, la meccanica quantistica è stata introdotta per spiegare fenomeni che la fisica classica non riusciva a descrivere. Successivamente si è compreso che la meccanica classica non era errata, ma rappresentava un caso limite della teoria quantistica.
Lo stesso schema si applica all’informazione. “La quantum information theory è la teoria generale; quella classica diventa un caso limite”, afferma Curioni.
Quando il sistema si comporta in modo “classico”, utilizzare il modello classico resta più semplice ed efficiente. Ma il quadro teorico di riferimento diventa quello quantistico, perché è in grado di descrivere un insieme più ampio di fenomeni.
Il riconoscimento scientifico
Questo passaggio teorico ha ricevuto anche un riconoscimento formale recente.
Curioni richiama il Turing Award assegnato ai pionieri della quantum information theory, tra cui Charles Bennett di IBM, proprio per il contributo alla ridefinizione della teoria dell’informazione in chiave quantistica.

Il riferimento non è simbolico. Serve a collocare il quantum computing non solo come evoluzione tecnologica, ma come passaggio nella teoria stessa dell’informazione.
Architettura e valore
Nel modello quantum-centric, il valore non è distribuito in modo uniforme nel sistema. Il processore quantistico diventa l’elemento più critico e più differenziante; tutte le altre componenti sono progettate per supportarlo.
Questo cambia il modo in cui vengono progettati i sistemi, ma anche il modo in cui viene distribuito il valore tecnologico e industriale: il vantaggio competitivo si sposta verso chi è in grado di progettare, integrare e utilizzare al meglio questo nuovo centro del sistema.
Reference architecture: una base, non una piattaforma chiusa
Il framework di integrazione tra HPC e quantum non è concepito come uno stack proprietario chiuso. Curioni chiarisce esplicitamente la scelta: “Abbiamo definito una reference architecture non per noi, ma per il mondo”.
Il punto non è costruire un ambiente controllato esclusivamente da IBM, ma definire un modello di riferimento coerente con lo stato dell’arte del quantum hardware e con la sua evoluzione nei prossimi anni.
Questa architettura di riferimento descrive come devono essere integrati quantum computer, sistemi classici e, quando necessario, infrastrutture cloud. Non si tratta di una specifica astratta, ma di un’indicazione operativa: quali componenti devono dialogare, con quali livelli di controllo, con quali modalità di gestione dei dati.
La scelta di una reference architecture risponde a un problema preciso: la frammentazione. “L’obiettivo è evitare che ognuno costruisca il proprio modo di integrare quantum e classical”, osserva Curioni.
In una fase iniziale di una tecnologia, è frequente che emergano approcci diversi e incompatibili tra loro. Questo rallenta lo sviluppo dell’ecosistema, perché costringe sviluppatori e aziende a lavorare su piattaforme non interoperabili.
Definire una base comune serve a ridurre questo rischio. Non elimina la competizione, ma la sposta su un livello diverso: non sull’infrastruttura di base, ma sui componenti che si costruiscono sopra.
Un modello di ecosistema
Il quantum computing, nella visione di Curioni, è destinato a svilupparsi come un ecosistema. Diversi attori – aziende tecnologiche, partner, sviluppatori – contribuiranno alla costruzione di soluzioni sopra una base comune. La reference architecture diventa quindi un punto di convergenza, perché consente a chi sviluppa di comprendere come collegarsi ai sistemi quantistici, permette di integrare classical computing e cloud in modo coerente e definisce un linguaggio comune tra componenti diversi, riducendo la complessità delle interazioni tra ambienti eterogenei. Non è un vincolo rigido, ma una struttura di riferimento che rende possibile la collaborazione.
Il ruolo di IBM nell’ecosistema
IBM, in questo contesto, si posiziona come fornitore della base tecnologica e architetturale. “Questa è la reference architecture, questo è il modo corretto – allo stato dell’arte – di mettere insieme quantum, classical e cloud”, è il senso della posizione espressa da Curioni. Non si tratta di imporre uno standard chiuso, ma di proporre un modello che altri possano adottare, estendere o integrare.
Le aziende che costruiranno applicazioni potranno collegarsi ai sistemi quantistici IBM, ma anche ad altri sistemi di classical computing e a infrastrutture cloud, operando all’interno di un’architettura coerente che evita integrazioni ogni volta diverse.
In questo modello, il valore non è concentrato esclusivamente nell’hardware. La reference architecture definisce una base comune su cui si sviluppano componenti differenzianti, come applicazioni, strumenti di orchestrazione e soluzioni verticali per specifici settori. Il vantaggio competitivo si sposta quindi su ciò che viene costruito sopra l’infrastruttura, più che sulla semplice disponibilità della tecnologia.
L’obiettivo è costruire un ambiente in cui problemi complessi possano essere affrontati senza dover ricostruire ogni volta l’integrazione tra i diversi livelli tecnologici. Quantum, classical computing e cloud non vengono più trattati come ambienti separati, ma come parti di un’unica architettura, accessibile attraverso interfacce comuni e modelli condivisi.
In una prima fase, questo livello non può che essere definito da chi progetta l’architettura. “Quando si realizza una reference architecture, l’orchestrazione iniziale viene definita da chi la costruisce”, spiega Curioni.
Nel caso di IBM, questo significa che l’orchestrazione è gestita attraverso software proprietari, che mettono a disposizione API e strumenti di sviluppo in grado di distribuire i workload tra ambienti diversi. In questa configurazione, la scelta su dove eseguire una determinata parte del problema – su sistemi classici, su quantum computer o su infrastrutture cloud – è guidata da un insieme di regole incorporate nel framework stesso.
Queste regole riflettono lo stato attuale delle tecnologie: tengono conto delle capacità relative dei diversi sistemi, del tipo di operazione da eseguire, delle condizioni operative e delle risorse disponibili. Non si tratta quindi di una distribuzione casuale, ma di una logica codificata che assegna ogni componente del problema al dominio più adatto.
Dalle regole all’adattività
Il modello attuale non è però completamente statico. Curioni precisa che, pur essendo basata principalmente su regole, l’orchestrazione include già elementi di adattività. “Alcune funzioni utilizzano già l’intelligenza artificiale”, osserva.
Questo significa che il sistema non si limita ad applicare schemi predefiniti, ma è già in grado di introdurre una prima forma di ottimizzazione dinamica, adattando la distribuzione dei carichi in funzione delle condizioni reali di esecuzione.
Con l’aumento della complessità dei sistemi, questo approccio è destinato a evolvere.
“In futuro, l’orchestrazione diventerà sempre più AI-based”, afferma Curioni.
Il motivo è legato alla natura stessa dell’architettura. Man mano che cresce il numero di componenti coinvolti – quantum processor, sistemi HPC, cloud, reti di interconnessione – aumenta anche il numero delle variabili da considerare. In queste condizioni, un sistema basato esclusivamente su regole statiche non è più sufficiente.
L’intelligenza artificiale diventa quindi il livello in grado di gestire questa complessità. Può valutare in tempo reale lo stato del sistema, individuare il dominio più efficiente per ogni operazione e adattare continuamente le strategie di esecuzione. Non si tratta di un miglioramento incrementale, ma di un passaggio necessario per rendere operativa un’infrastruttura ibrida su larga scala.
Un livello aperto all’ecosistema
Questo livello di orchestrazione non è destinato a rimanere confinato all’interno di un singolo fornitore. Curioni sottolinea che, con lo sviluppo dell’ecosistema, emergeranno altri attori in grado di costruire soluzioni di orchestrazione sopra la reference architecture. “Anche altri creeranno orchestrazione sopra questa architettura”, afferma.
L’orchestrazione diventa quindi uno dei punti principali di differenziazione. Non è solo un elemento tecnico di supporto, ma una componente su cui si giocherà una parte significativa del valore, perché determina l’efficienza complessiva del sistema e la capacità di sfruttare realmente le diverse modalità di computing.
AI e quantum: livelli diversi dello stack
Il tema dell’orchestrazione porta direttamente a chiarire il rapporto tra intelligenza artificiale e quantum computing.
Curioni mette in guardia da una rappresentazione diffusa che li colloca sullo stesso piano. “Si tende a considerare AI e quantum come due tecnologie parallele, ma non è così”.
La distinzione è netta: “Il quantum è una tecnologia abilitante del computing, mentre l’AI è un’applicazione del computing”.
Questo implica una struttura gerarchica. Classical computing e quantum computing costituiscono il livello infrastrutturale, cioè il fondamento su cui vengono eseguite le operazioni. L’AI si colloca sopra, come livello applicativo, utilizzando entrambe le tecnologie per sviluppare modelli, analisi e sistemi decisionali.
L’AI come fattore di ottimizzazione
Allo stesso tempo, l’AI non è soltanto utilizzatrice delle infrastrutture, ma contribuisce a migliorarle.
Curioni osserva che l’intelligenza artificiale può intervenire direttamente nella gestione del sistema, rendendo più efficiente l’interazione tra classical e quantum computing. “L’AI aiuterà a fare classical e quantum meglio, perché permette di orchestrare e automatizzare i processi”, afferma.
In questo senso, l’orchestrazione AI-based rappresenta il punto di incontro tra i diversi livelli dell’architettura: da un lato utilizza le capacità computazionali disponibili, dall’altro ne ottimizza il funzionamento, contribuendo a rendere sostenibile l’evoluzione verso sistemi sempre più complessi e integrati.
Dal vantaggio scientifico al valore economico
Il quantum advantage in senso formale non coincide automaticamente con un vantaggio di business.
Curioni distingue chiaramente i due piani. Il primo riguarda la dimostrazione che un problema è affrontabile in modo più efficiente con il quantum. Il secondo riguarda l’impatto economico che questa capacità può generare.
Nel breve periodo, i due aspetti non sono necessariamente allineati. La simulazione molecolare può produrre risultati scientificamente rilevanti, ma con effetti economici indiretti o distribuiti nel tempo, ad esempio nello sviluppo di nuovi materiali o farmaci. Per il business, l’impatto più immediato si colloca altrove.
Ottimizzazione: il terreno dell’impatto economico
Curioni identifica con precisione il dominio in cui il quantum può generare valore economico nel medio termine. “Il maggiore impatto per il business arriverà dai problemi di global optimization”. Non si tratta di problemi teorici isolati, ma di una classe molto ampia di situazioni operative reali, caratterizzate da molte variabili e da obiettivi multipli, spesso in tensione tra loro.
“Non è più solo il travelling salesman problem: è multi-variable, multi-objective optimization”, sottolinea.
In questi contesti, il problema non è semplicemente trovare una soluzione, ma individuare il miglior compromesso possibile tra vincoli, costi, tempi e risorse. Gli esempi che Curioni porta sono espliciti e operativi.
Nel caso delle compagnie aeree, il problema è una combinazione di variabili che devono essere gestite simultaneamente: disponibilità degli aeromobili, rotte, slot aeroportuali, equipaggi, supply chain dei servizi di bordo.
“Le compagnie aeree devono ottimizzare slot, aerei, rotte, equipaggio, supply chain… e farlo in tempi molto brevi, soprattutto quando si verifica un imprevisto”. La complessità non è solo numerica, ma dinamica: ogni variazione si propaga sull’intero sistema e richiede una nuova configurazione.
Un secondo esempio riguarda l’organizzazione di eventi globali, come le Olimpiadi.
“Devi decidere quando far gareggiare gli atleti, in quali location, con quali vincoli di broadcasting e considerando anche dove nel mondo avranno più audience”.
Anche in questo caso, il problema non è lineare: le decisioni influenzano simultaneamente più dimensioni e il valore finale dipende dalla qualità complessiva della soluzione.
In questi contesti, anche miglioramenti relativamente contenuti nella qualità dell’ottimizzazione possono produrre effetti significativi. “Se lo fai bene, non guadagni un milione. Guadagni centinaia di milioni”.
Il quantum computing, quindi, non interviene come una tecnologia marginale, ma come un possibile fattore di leva su problemi che hanno già oggi un impatto economico rilevante.
Quantum machine learning: un campo ancora aperto
Accanto alla simulazione e all’ottimizzazione, Curioni individua un terzo ambito di sviluppo: il quantum machine learning. Il giudizio è prudente ma aperto. “Ci sono state fasi di grande entusiasmo e altre di disillusione”, osserva, riconoscendo che il campo non ha ancora prodotto risultati definitivi.
Allo stesso tempo, non lo considera marginale: la diversa rappresentazione dell’informazione potrebbe introdurre nuove modalità di apprendimento e di elaborazione dei dati.
“È un ambito in cui ci aspettiamo sviluppi interessanti”, conclude.
Europa: competenze solide, ritardo infrastrutturale
Il posizionamento europeo nel quantum computing, secondo Curioni, è caratterizzato da una forte asimmetria tra capacità scientifiche e sviluppo industriale.
Sul piano delle competenze e della ricerca di base, il giudizio è netto: “Abbiamo sviluppato gran parte delle idee che stanno alla base di queste tecnologie e, dal punto di vista delle competenze, non siamo secondi a nessuno”.
L’Europa continua a esprimere centri di ricerca e scuole scientifiche di altissimo livello, in grado di contribuire in modo diretto all’evoluzione del quantum computing e della teoria dell’informazione. Il quadro cambia quando si passa al livello infrastrutturale.
“Siamo parecchio indietro rispetto a Stati Uniti e Cina; direi almeno cinque anni, se non di più”, afferma Curioni.
Il ritardo riguarda la capacità di sviluppare, industrializzare e scalare le tecnologie, non la comprensione teorica. Questo significa che l’Europa rischia di trovarsi nella posizione di contribuire alle basi scientifiche senza riuscire a capitalizzarle pienamente sul piano industriale.
Questo divario introduce un rischio strategico: “e concentriamo tutte le risorse per recuperare il gap infrastrutturale, rischiamo di trascurare lo sviluppo dell’ecosistema software e applicativo”.
Curioni sottolinea che il valore economico non si concentra solo nell’hardware. Storicamente, è nel software, negli algoritmi e nelle applicazioni che si genera la parte più consistente del valore.
Il punto, quindi, non è scegliere tra infrastruttura e applicazioni, ma evitare uno squilibrio che penalizzi la capacità di costruire un ecosistema completo.
Una finestra ancora aperta
Nonostante il ritardo, esiste ancora uno spazio di manovra. Nel campo del software e delle applicazioni, la competizione non è ancora definita. Non esiste un attore dominante paragonabile a quello che è stato, in altri ambiti, la Silicon Valley. Questo significa che l’Europa può ancora posizionarsi, costruendo competenze e soluzioni in una fase in cui gli equilibri non sono ancora stabilizzati.
Il problema principale, però, non è solo tecnologico. “Se ci presentiamo con 27 strategie diverse, non andiamo da nessuna parte”, osserva Curioni.
La frammentazione delle iniziative, delle politiche industriali e degli investimenti rischia di ridurre l’efficacia complessiva degli sforzi europei, soprattutto in un contesto in cui i principali competitor operano con maggiore coesione.
Il contesto competitivo è cambiato rispetto al passato: non esiste più un solo punto di riferimento globale, ma almeno due poli principali – Stati Uniti e Cina – che stanno investendo in modo significativo nello sviluppo del quantum computing. In questo scenario, la dispersione delle risorse rappresenta un limite strutturale.
La conclusione di Curioni è diretta: “Tra il dire e il fare c’è una distanza significativa. L’unica possibilità di fare la differenza è unire le forze”.
Senza un coordinamento tra Paesi, investimenti e strategie, il rischio è quello di rimanere su un piano di dichiarazioni e iniziative isolate, senza riuscire a incidere realmente sullo sviluppo del settore. “Altrimenti possiamo avere buone intenzioni, ma non riusciremo a ottenere risultati concreti”.






{kind=link}