

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco, professore associato presso l’Università Luiss Guido Carli.
Nella puntata di oggi vorrei parlarvi di quello che potrebbe essere il futuro dopo i Transformers, l’architettura alla base dei Large Language Models, tanto discussa all’interno di questa rubrica.
Parliamo in particolare dell’architettura JEPA, proposta principalmente dal Premio Turing Yann LeCun.
Di cosa si tratta e perché uno dei più grandi scienziati dietro alla rivoluzione del deep learning sta proponendo questa metodologia alternativa? A che punto siamo nel suo sviluppo? Scopriamolo insieme in questa puntata di Le Voci dell’AI.
L’architettura Transformers, introdotta nel 2017 con il paper Attention Is All You Need, ha rappresentato una delle più profonde rivoluzioni nella storia dell’intelligenza artificiale.
Basata sul concetto di attenzione, essa ha permesso ai modelli di apprendere le relazioni contestuali complesse tra parole e immagini o suoni, superando le limitazioni delle reti ricorrenti e convenzionali classiche.
L’idea chiave – pensare dinamicamente l’importanza di ogni elemento di input rispetto agli altri nel suo contesto – ha reso possibile una comprensione profonda e scalabile dei dati sequenziali.
Da questa innovazione è nata una nuova generazione di modelli linguistici di grandi dimensioni, Large Language Models, culminata in sistemi come GPT-5, oggi tra i modelli fondazionali più potenti e versatili mai sviluppati.
GPT5 non è solo un’evoluzione in termini di dimensioni, come sappiamo, ma soprattutto di capacità di ragionamento, adattabilità e generalizzazione, dimostrando come la semplice estensione del paradigma dei Transformers dal 2017 possa condurre oggi a risultati di sorprendente complessità emergente.
Nonostante i grandi progressi la legge dei rendimenti decrescenti sta iniziando a manifestarsi anche per i Transformers. Ogni incremento marginale in prestazioni richiede risorse computazionali, energetiche ed economiche sempre più elevate con benefici sempre meno proporzionati.
Questa tendenza sta spingendo la comunità scientifica a interrogarsi sul futuro oltre i Transformers.
Molti ricercatori esplorano quindi nuove architetture ispirate alla biologia come modelli neurali ibridi, le reti di memoria esplicita o approcci simbolico connessi a misti, che combinano l’apprendimento profondo e il ragionamento logico.
L’obiettivo è superare i limiti di efficienza e generalizzazione attuali, aprendo la strada a una nuova onda tecnologica che, pur ereditando i principi di attenzione rappresentazione contestuale, potrebbe fondarsi su paradigmi radicalmente diversi, forse più vicini ai meccanismi cognitivi naturali dell’intelligenza umana.
Yann LeCun, pioniere dell’intelligenza artificiale, figura chiave nello sviluppo delle reti neurali convoluzionali, è considerato uno dei padri fondatori del deep learning moderno e le sue CNN hanno rivoluzionato il campo della visione artificiale e reso possibili applicazioni che oggi diamo per scontate, come il riconoscimento facciale, la classificazione di immagini e la guida autonoma.
Tuttavia, da alcuni anni LeCun sta tracciando una nuova direzione nella ricerca per l’AI, criticando apertamente l’attuale predominio dei modelli basati su Transformers e proponendo un paradigma alternativo più vicino ai meccanismi di apprendimento autosupervisionato che si ipotizzano avvengano nel cervello umano.
Il cuore di questa visione è JAPA – Joint Embedding Predictive Architecture, un’architettura concettualmente diversa rispetto agli approcci auto regressivi dei modelli linguistici come GPT.
JAPA non mira a prevedere direttamente il prossimo token, la prossima parola, il prossimo pixel, ma piuttosto a predire rappresentazioni latenti di porzioni mancanti o future dei dati, imparando quindi a costruire una comprensione astratta e coerente del mondo.
In questa architettura due reti componenti fondamentali, un encoder e un predictor, lavorano insieme per confrontare rappresentazioni.
L’encoder crea una mappa compatta del contesto osservato, mentre il predictor cerca di stimare la rappresentazione di una parte mancante del segnale, senza mai dover generare esplicitamente l’input grezzo.
Questo consente di evitare il costoso e talvolta inefficiente processo di attenzione globale tipico dei Transformers e più costoso dal punto di vista computazionale.
Il principio fondamentale è che il cervello non elabora ogni dettaglio di una scena o di un discorso, ma costruisce modelli predittivi del mondo a un livello semantico più astratto, anticipando i concetti e le strutture piuttosto che simboli elementari.
LeCun e il suo team nel tempo hanno proposto diverse varianti ed evoluzioni dell’architettura, tra cui I-JEPA (Image-JEPA) per la comprensione visiva di immagini e V-JEPA per la modellazione temporale, quindi di video, oltre a versioni multimodali che integrano suoni e anche testo.
I risultati preliminari mostrano che questi sistemi sono più efficienti, senz’altro richiedono meno dati etichettati e offrono rappresentazioni generalizzabili utili a molteplici compiti, senza bisogno di un processo di raffinamento supervisionato significativo, soprattutto nel contesto della visione artificiale.
Quindi, sebbene modelli JEPA non abbiano ancora raggiunto le prestazioni dei grandi modelli basati su Attention, il loro approccio teoricamente basato sulla produzione di rappresentazioni latenti piuttosto che di simboli, suggerisce una possibile nuova via per l’AI Generale, più economica e scalabile e cognitivamente ispirata, capace di apprendere in un modo autonomo e continuo, come fanno gli esseri viventi.
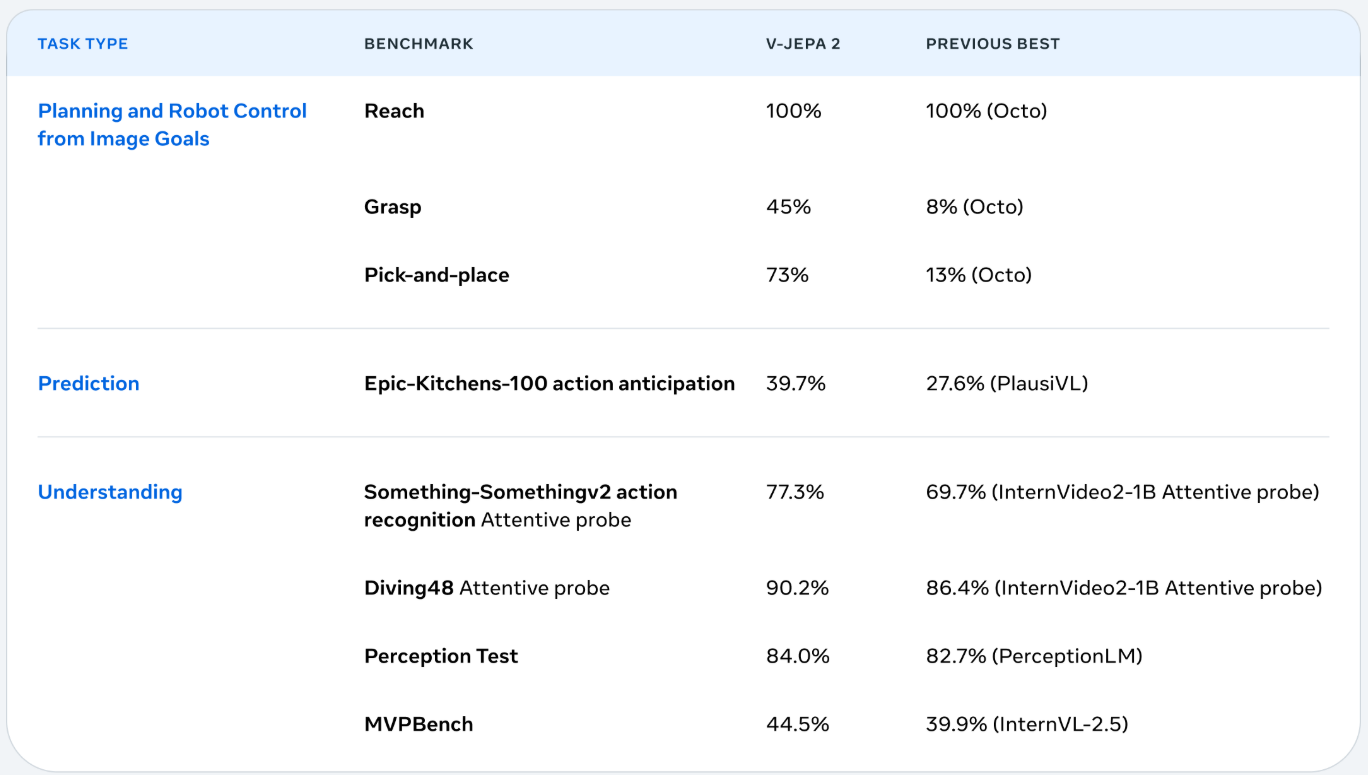
In questa immagine vediamo i risultati impressionanti ottenuti dal modello V-JEPA 2, presentato nell’articolo, recentemente pubblicato, V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning, che rappresenta l’ultima e più avanzata incarnazione della linea di ricerca di Yann LeCun con suoi modelli Joint Embedding Predictive Architecture – JEPA applicati principalmente ai video naturali.
Questa nuova architettura self-supervised punta a costruire una comprensione predittiva del mondo visivo senza fare uso di attention, meccanismo tipico dei Transformers, come dicevamo, e i dati mostrano un netto miglioramento su una vasta gamma di benchmark che spaziano dalla pianificazione robotica alla comprensione e previsione di azioni visive nel campo del Planning e Robot Control from Image Goals questo modello raggiunge risultati davvero interessantissimi e mantiene il 100% di successo nel compito Reach e ottiene enormi progressi rispetto allo stato dell’arte nei task Grasp e Pick-and-place,
Addirittura il 45% rispetto all’8%, 73% rispetto al 13% e così via, indicando una capacità emergente di ragionamento spaziale motorio basato sulla pura osservazione visiva.
Anche nel dominio della prediction, cioè predire quello che succederà in futuro, il modello mostra un netto salto prestazionale con un circa 40% nella Epic Kitchens-100 action anticipation superando il precedente stato dell’arte di una decina di punti.
I miglioramenti più significativi si osservano però nell’area dell’Understanding, dove JEPA dimostra di aver appreso rappresentazioni video profondamente semantiche, con prestazioni davvero interessanti su diversi benchmark come Something-Something versione 2 Diving48 e molti altri.
Questi risultati evidenziano non solo l’efficacia dell’apprendimento predittivo auto supervisionato, ma anche il potenziale di un’architettura che riesce a catturare dinamiche complesse e regolarità del mondo reale, senza dover analizzare sequenze frame by frame con meccanismi di attenzione globale.
V-JEPA 2 segna così un passo cruciale verso un’intelligenza artificiale capace di comprendere, anticipare e pianificare in modo autonomo, combinando efficienza e generalizzazione.
Se i Transformers hanno insegnato alle macchine a leggere e scrivere, i modelli JEPA potrebbero essere quelli che finalmente insegneranno le macchine a capire e pensare.
Ciao! Alla prossima puntata di Le Voci dell’AI.