

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco, ricercatore e docente all’Università di Pisa.
Nella puntata di oggi parliamo di un tema molto caldo in questi ultimi mesi nel mondo dell’intelligenza artificiale, ossia come connettere un Large Language Model a strumenti e sorgenti dati esterni anche non necessariamente disponibili all’interno di una singola organizzazione o soluzione software.
A che punto siamo rispetto a questa idea di usare quindi Large Language Models come orchestratore di servizi e microservizi? Ci sono degli esempi rilevanti in tal senso? Scopriamolo insieme in questa puntata di Le Voci dell’AI.
Negli ultimi anni si è assistito a un’evoluzione significativa nell’uso di modelli del linguaggio naturale, Large Language Models che da semplici generatori di testo basati su conoscenza pre addestrata, si stanno trasformando in agenti intelligenti capaci di interagire autonomamente con risorse esterne.
L’idea centrale è utilizzare quindi il linguaggio naturale non solo come mezzo di comunicazione con gli esseri umani, gli utenti, ma come interfaccia universale per accedere a dati, strumenti, Api esterne presenti nel web, per esempio.
In questo nuovo paradigma i Large Language Models non cercano più di sapere tutto, ma diventano orchestratori in grado di selezionare e utilizzare strumenti specializzati per costruire soluzioni specializzate, rispondendo a esigenze via via più complesse.
In questo contesto si inseriscono progetti come Olympus che abbiamo discusso nella puntata numero 100 di questa rubrica o HuggingGPT, che sfrutta un Large Language Model per coordinare modelli verticali presenti su HuggingFace Model Hub per la visione, la classificazione, la traduzione, ecc. delegando di fatto i sottocompiti in base alla richiesta dell’utente.
Similmente, Gorilla affronta il problema dell’invocazione precisa di Api, addestrando modelli su documentazione reale per generare chiamate robuste e corrette sintatticamente.
Una delle proposte recenti più ambiziose è quella di Agent2Agent (A2A), un protocollo di comunicazione introdotto da Google, in cui agenti LLM possono comunicare tra loro e cooperare tramite linguaggio naturale per risolvere task complessi.
In A2A ogni agente ha accesso a strumenti e competenze differenti e può chiedere aiuto ad altri agenti tramite messaggi testuali, creando così un ambiente collaborativo, distribuito e scalabile.
Questa architettura si sposa anche molto bene con l’idea del Model Context Protocol, MCP, che consente a modelli di linguaggio naturale di accedere a contesti esterni in modo controllato e dinamico.
Insieme, queste tecnologie delineano un futuro in cui il margine i Large Language Models non solo comprendono e generano linguaggio, ma agiscono e attivamente come nodi intelligenti di una rete di agenti e servizi interoperabili.
Ecco, in queste immagini analizziamo più nel dettaglio la soluzione di Gorilla, a titolo esemplificativo.
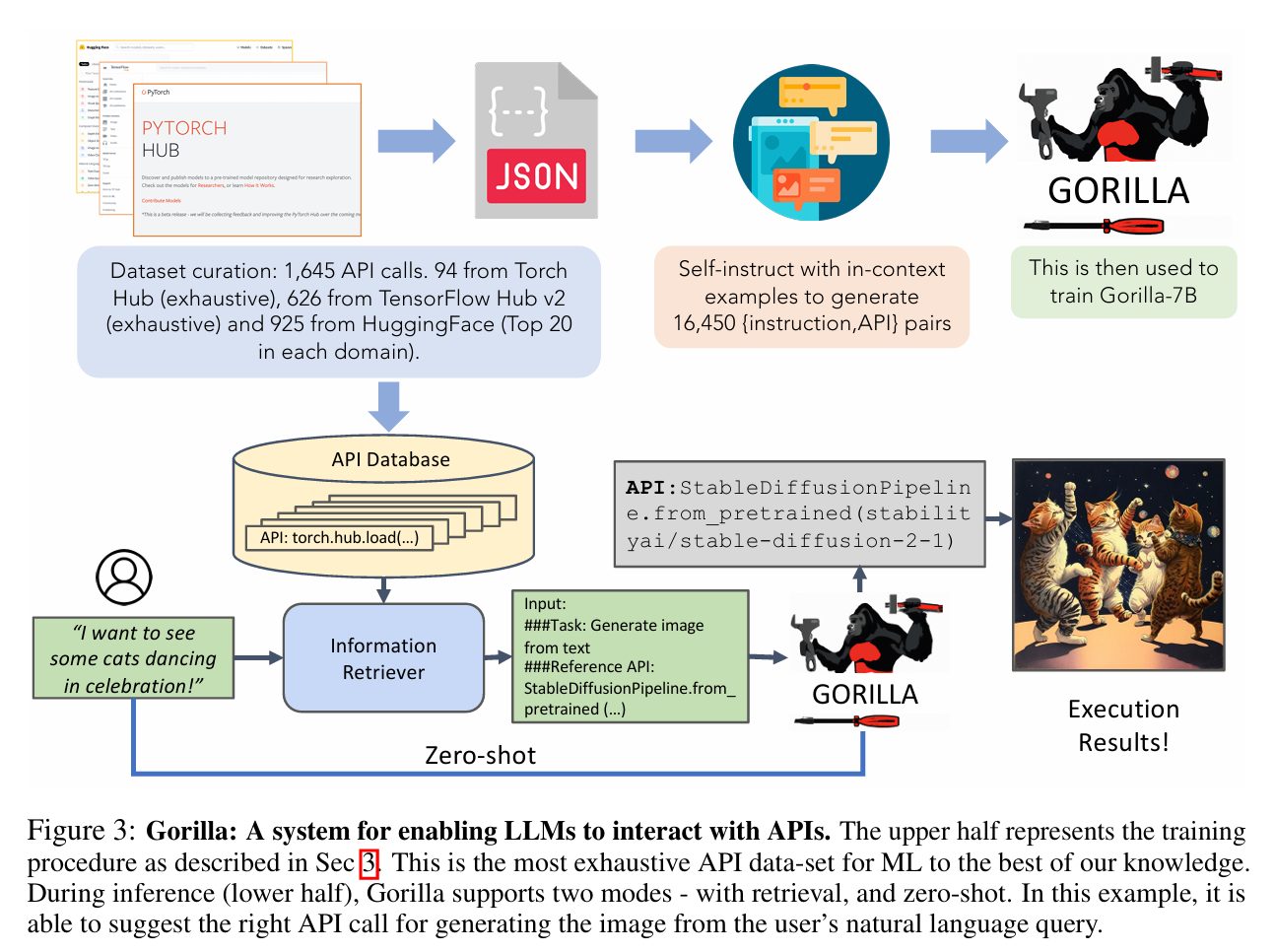
Gorilla è un sistema progettato per permettere a modelli di linguaggio di grandi dimensioni di interagire efficacemente con Api (Application Programming Interfaces) esterne.
La pipeline di Gorilla si divide in due fasi principali: una fase di addestramento, in alto e una fase di inferenza, in basso quando utilizziamo effettivamente il sistema.
Durante la fase di addestramento, gli autori hanno curato un dataset di circa 1600 chiamate di Api provenienti da tre fonti principali.
A titolo esemplificativo Torch Hub, TensorFlow Hub e HugginFace Model Hub.
Le specifiche Api raccolte sono state realizzate in formato Json e utilizzate per costruire un database centralizzato di Api.
Successivamente, con un approccio chiamato Self-instruct Gorilla genera automaticamente 16.000 copie Istruzione – Api quindi input, prompt, richiesta dell’utente e corrispettiva API da selezionare per risolvere quel problema.
Questi dati sintetici sono poi utilizzati per addestrare un modello, Gorilla-7B, un LLM specializzato nell’associare istruzioni in linguaggio naturale alle chiamate Api corrispondenti.
Durante l’inferenza Gorilla opera in due modalità: zero-shot e con retrieval del flusso inferenziale mostrato.
Un utente formula le richieste in linguaggio naturale, come ad esempio “I want to see some cats dancing in celebration”, “Voglio vedere dei gatti che danzano festeggiando” Questa richiesta viene analizzata da un sistema di recupero informazioni che consulta il database delle Api per trovare chiamate potenzialmente rilevanti; le informazioni recuperate e la richiesta dell’utente vengono poi passate a Gorilla che identifica e seleziona la Api più adatta da utilizzare.
In questo caso Gorilla seleziona correttamente la funzione StableDiffusionPipeline.from_pretrained per generare un’immagine da testo corrispondente alla richiesta espressa.
L’output è una generazione visiva coerente con l’istruzione, come mostrato nel risultato con i gatti danzanti.
L’intero processo può avvenire anche in modalità zero-shot, dove il modello predice direttamente l’Api giusta senza ricorrere al sistema di retrieval, questo passaggio intermedio.
Gorilla, quindi, rappresenta un significativo passo in avanti nell’integrazione tra modelli di linguaggio e sistemi software, consentendo di tradurre comandi espressi in linguaggio naturale in chiamate di Api realmente eseguibili, scritte con la sintassi corretta.
La forza del sistema risiede sia nell’estensione e varietà del dataset di addestramento, sia nell’approccio self construct che consente la scalabilità del training, rendendo Gorilla uno strumento molto promettente per l’automazione di task complessi tramite Large Language Models.
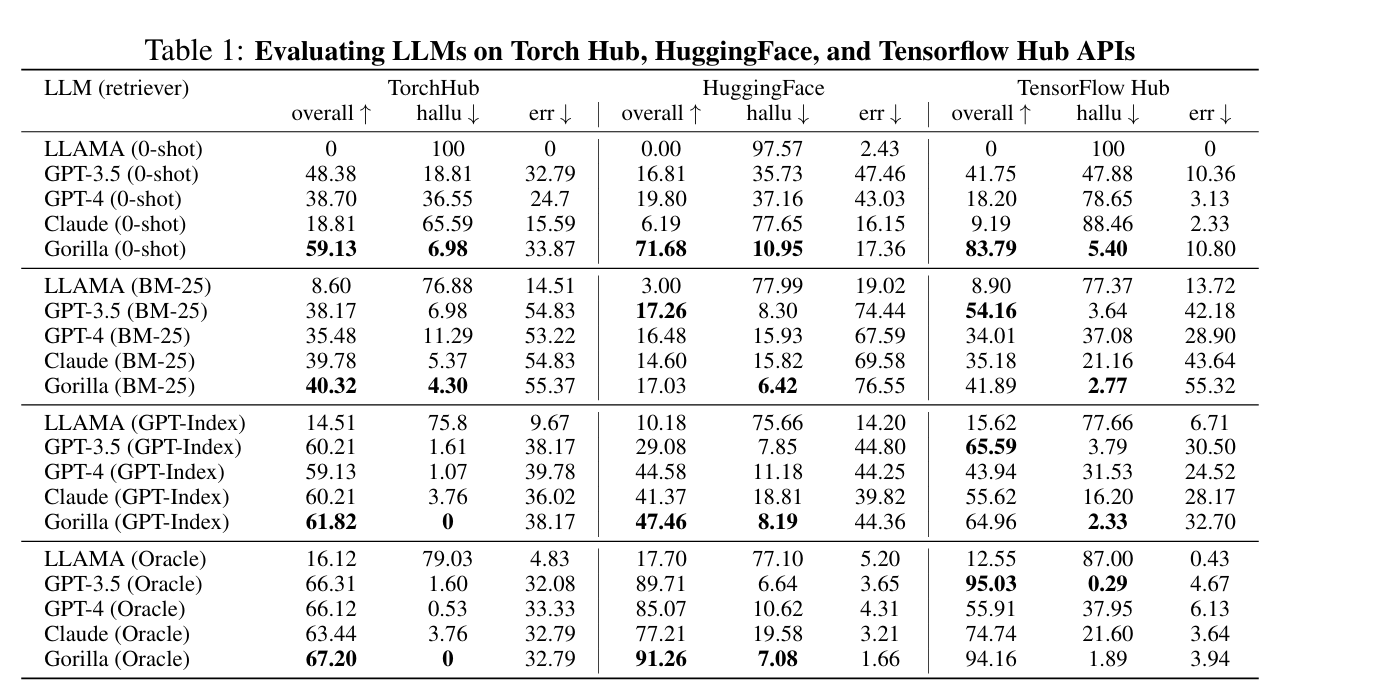
In questa tabella invece, vediamo un confronto empirico tra vari Large Language Model: Llama, GPT 3.5, GPT 4 Claude e Gorilla su 3 benchmark di API, TorchHub, HuggingFace e Tensorflow Hub, usando tre metriche principali: accuratezza complessiva della selezione di Api, tasso di allucinazioni e percentuale di errori nell’uso di un’Api.
I modelli sono valutati in quattro scenari di retrieval: zero shot senza nessun contesto BM-25 con un retrieval classico, GPT-index con un retrieval intelligente e Oracle con un contesto perfetto.
Gorilla eccelle in quasi tutte le impostazioni, come vediamo; in zero-shot, per esempio supera tutti con 59,13 su TorchHub, 71,68 in HuggingFace, 83,79 su Tensorflow Hub, riducendo drasticamente le allucinazioni, ovvero generazione di sintassi non corretta nell’uso delle Api in modalità BN 25 Gorilla resta poi competitivo, ma i modelli tendono a soffrire per errori residui dovuti al recupero limitato con GPT-Index Gorilla raggiunge 61,82 su TorchHub mantiene allucinazioni nulle, 0, dimostrando quindi eccellente robustezza quando il contesto viene selezionato bene.
Claude e GPT 3.5 ottengono risultati comunque simili, anche se Gorilla si distingue per un miglior bilanciamento tra accuratezza alta e allucinazioni minime.
Teniamo conto che anche Gorilla è un modello piuttosto piccolo, con 7 miliardi di parametri.
Nella modalità Oracle, dove il contesto è perfetto, Gorilla raggiunge il massimo, 67 circa su TorchHub, 91 su HuggingFace, 94 su TensorFlow Hub, con allucinazioni quasi nulle e errori minimi.
In sintesi, da questa analisi empirica quello che emerge è che il modello più efficace e affidabile nella comprensione, nell’esecuzione di chiamate Api specialmente in scenari senza allucinazioni e con contesto ottimale, in particolare mostra eccellente generalizzazione sia in ambito zero-shot sia in modalità avanzate, superando costantemente gli altri Large Language Models nella scelta del dominio corretto e della funzione e più adatta, rendendolo quindi lo strumento migliore almeno in questi tre domini, con questo tipologia di Api.
Bene, In questa puntata abbiamo discusso di questo nuovo approccio, sempre più popolare nell’uso dei Large Language Models come interfaccia automatica con strumenti e sorgenti dati esterni in funzione del compito e del bisogno informativo dell’utente.
In particolare abbiamo analizzato Gorilla, una delle prime soluzioni e strumenti sviluppati in tal senso che si concentra sulla ricerca degli strumenti più idonei al movimento di un compito, disponibili liberamente in rete.
Del futuro non potremo che aspettarci significativi sviluppi nella ricerca e orchestrazione di strumenti esterni, laddove un singolo modello statico e monolitico ha già dimostrato di essere inefficace rispetto alla risoluzione di compiti via via più complessi.
Ciao! Alla prossima puntata di Le Voci dell’AI.