

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco, ricercatore e docente all’Università di Pisa.
Nella puntata di oggi parliamo di una metodologia di intelligenza artificiale fondamentale per la generazione di immagini sintetiche di eccezionale qualità.
Parliamo di Modelli di Diffusione Stabile, ossia di un processo ispirato alla fisica per la generazione di immagini a partire da pixel casuali.
Qual è l’impatto applicativo di questa tecnologia e dove viene più spesso utilizzata? Quali sono le alternative per generare immagini di qualità a partire da un prompt testuale? Scopriamolo insieme in questa puntata di Le Voci dell’AI.
Negli ultimi anni la generazione di immagini sintetiche ma realistiche ha compiuto enormi progressi nel campo della visione artificiale, trasformandosi da un obiettivo di ricerca ambizioso a una tecnologia ampiamente applicata, come abbiamo già discusso nell’episodio 94 sull’ultimo modello di image generation di OpenAI.
Un punto di svolta fondamentale è stato l’introduzione delle Generative Adversarial Networks o GAN, proposte da Ian Goodfellow nel 2014.
Le GAN consistono in due reti neurali in competizione tra loro: un generatore che produce immagini sintetiche e un discriminatore che cerca di distinguere le immagini reali da quelle generate sinteticamente.
Questo meccanismo di apprendimento competitivo ha permesso la creazione di immagini fotorealistiche davvero interessanti dal punto di vista del dettaglio e della coerenza nella generazione portando allo sviluppo di varianti sempre più sofisticate come StyleGAN capace di controllare in modo preciso aspetti semantici dell’immagine come età, espressioni e soprattutto stile.
Tuttavia, le GAN mostrano ancora limiti nella stabilità dell’addestramento e nella diversità dei risultati.
Parallelamente si è assistito all’emergere dei modelli autoregressivi ispirati al successo dei Transformer e dalle architetture linguistiche tipo GPT.
In questo contesto, modelli come DALL·E hanno mostrato come si possano trattare le immagini come sequenze di token, apprendendo a generarle pixel by pixel in modo simile alla generazione del testo.
Questi modelli sfruttano enormi dataset e capacità computazionali davvero incredibili per apprendere la corrispondenza tra testo e immagini ottenendo una generazione altamente controllabile e coerente con l’input testuale.
L’evoluzione recente ha portato allo sviluppo di modelli multimodali come CLIP, Flamingo o GPT‑4V, che integrano visione e linguaggio in un’unica architettura permettendo sia la comprensione sia la generalizzazione in più modalità.
Questi modelli estendono il concetto di embedding condiviso tra testo e immagini migliorando la qualità semantica e la precisione contestuale delle immagini generate.
Infine, sebbene meno centrali in questa panoramica, i Modelli di Diffusione hanno rapidamente guadagnato terreno grazie alla loro capacità di produrre immagini di qualità davvero eccezionale, tramite un processo iterativo di denoising, di riduzione del rumore, superando spesso sia le GAN sia i modelli autoregressivi in termini di fedeltà visiva e stabilità modelli come Stable Diffusion e Imagen ne rappresentano esempi notevoli.
La generazione di immagini sintetiche realistiche, quindi, continua ad evolversi guidata da approcci sempre più integrati, scalabili e capaci di comprendere il linguaggio naturale e la struttura visiva con profondità crescente.
Quindi come funziona un Diffusion Model? Il nome Diffusion Model deriva dal suo processo fondamentale che imita la diffusione di calore o di particelle in un mezzo.
Il modello apprende gradualmente a invertire questo processo di diffusione per generare dati sintetici.
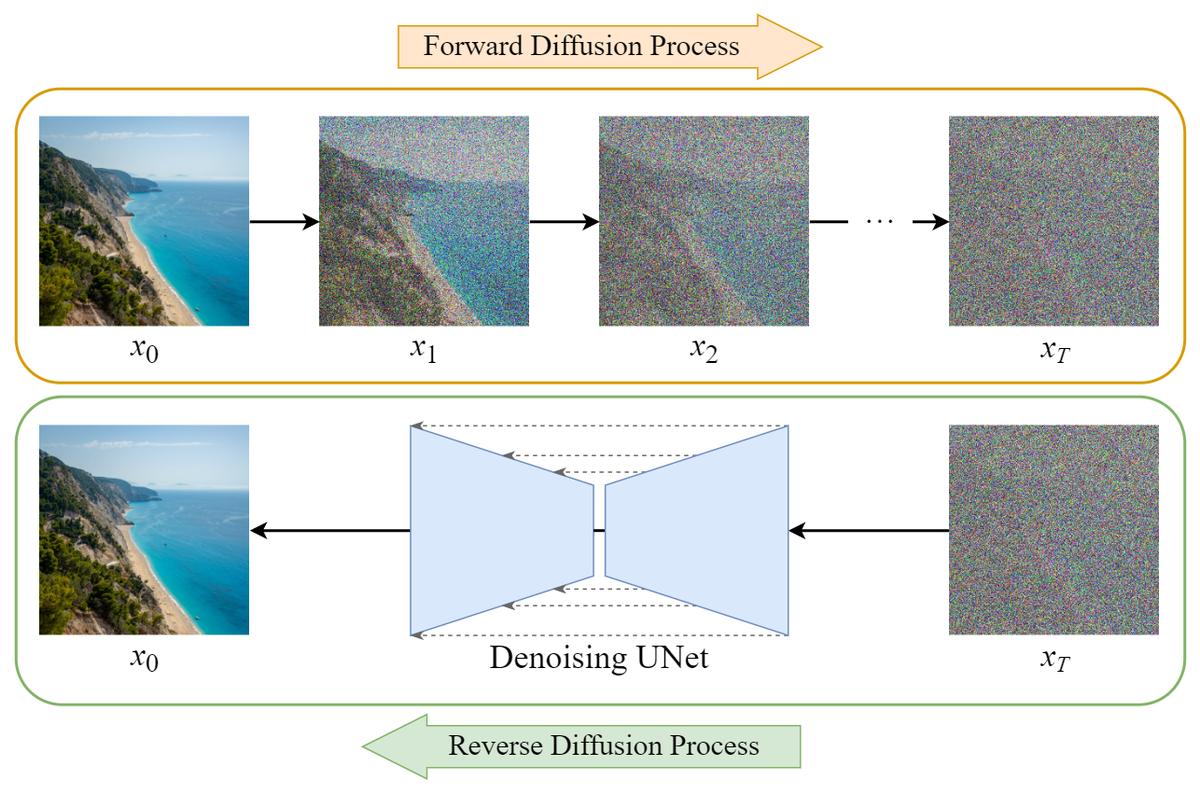
Come vediamo in questa immagine, il funzionamento di un Diffusion Model si articola in due fasi principali: il processo di Diffusione in Avanti, Forward Diffusion Process e il processo di Diffusione Inversa, Reverse Diffusion Process.
Nella fase di diffusione in avanti, a partire da un dato iniziale come l’immagine pulita x0 mostrata in alto a sinistra, viene aggiunto progressivamente del rumore gaussiano in piccoli incrementi nel corso di T passi Iterativi, trasformando quindi gradualmente il dato iniziale di input in un rumore puramente casuale xT.
Questo processo è markoviano, il che significa che lo stato al passo successivo dipende solo e soltanto dallo stato al passo corrente. La quantità di rumore aggiunta a ogni passo può essere controllata attraverso un programma di varianze, βT. L’obiettivo di questa fase è quello di apprendere come passare in modo controllato da l’immagine di qualità a del rumore pseudocasuale. La fase di diffusione inversa è invece il cuore della generazione partendo dal rumore casuale xT L’obiettivo è imparare a rimuovere sequenzialmente il rumore per ricostruire il dato originale x0. Questo viene fatto tramite una rete neurale, spesso una UNet addestrata a predire il rumore aggiunto in ogni passo del processo di diffusione in avanti.
Durante l’inferenza quindi questo modello viene utilizzato iterativamente per stimare e sottrarre il rumore partendo da un campione di rumore casuale e raffinandolo gradualmente fino a ottenere un campione di dati coerente come l’immagine xo mostrata in basso a sinistra. La capacità del modello, quindi di apprendere la transizione da una distribuzione di rumore semplice a una distribuzione di dati complessa come le immagini naturali appartenenti a un particolare ambito, è ciò che rende quindi i Diffusion Model potenti generatori di contenuti anche senza specifiche testuali direttamente partendo da del rumore.
L’architettura UNet quindi si è dimostrata particolarmente efficace in questo contesto, consentendo al modello di conservare informazioni a diverse scale durante il processo di denoising.
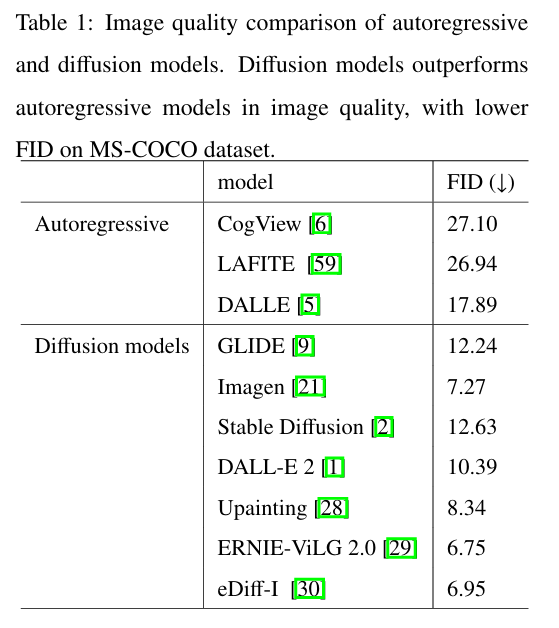
Questa tabella invece evidenzia chiaramente la superiorità dei Diffusion Model rispetto ai modelli auto regressivi nella generazione diimmagini di alta qualità, come Indicato dai valori inferiori della metrica Fréchet Inception Distance (FID) sul dataset MS COCO.
La FID è una metrica utilizzata per valutare la qualità delle immagini generate da un modello generativo, confrontando le statistiche delle feature estratte da un modello Inception v3 addestrato su immagini reali e immagini generate. Un valore FID più basso indica una maggiore similarità tra le distribuzioni dati delle feature delle immagini reali e quelle generate, suggerendo che le immagini generate sono più realistiche e fedeli al dataset di addestramento.
I Diffusion Model come GLIDE, Imagen, Stable Diffusion, DALL·E 2 e altri mostrano valori feed decisamente inferiori rispetto ai modelli autoregressivi come COGView, Lafite e persino il primo DALL·E, dimostrando una capacità superiore nel produrre immagini con maggiore coerenza strutturale, dettaglio e fedeltà al contenuto del dataset di partenza, riducendo artefatti e distorsioni che sono tipici nella generazione di immagini a partire da modelli auto regressivi.
Questa superiorità ha reso i Diffusion Model l’architettura di riferimento per la generazione di immagini di qualità, oggi.
Bene, in questa puntata abbiamo discusso più nel dettaglio di una metodologia fondamentale per la generazione di immagini sintetiche oggi, che ancora rappresenta lo stato dell’arte in termini di qualità e coerenza visiva nell’immagine.
Non è detto però che in futuro modelli auto regressivi multimodali come l’ultimissimo Image Generator di GPT-4o non siano in grado di migliorare la qualità di generazione ulteriormente abbassando anche i loro costi significativi e In ultima analisi superando l’ottimo compromesso offerto oggi dai modelli a diffusione stabile.
Ciao! Alla prossima puntata di Le Voci dell’AI!