

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco, ricercatore e docente all’Università di Pisa.
Nella puntata di oggi parliamo di un compito molto interessante alla base di tante, tantissime applicazioni di visione artificiale. Parliamo di colorazione automatica, ossia soluzioni di AI che a partire da un’immagine o video in bianco e nero – scala di grigi –, siano in grado di colorarlo, trasformarlo in un contenuto visivo a colori.
Come è possibile farlo oggi e quali sono le metodologie allo stato dell’arte? Qual è l’impatto applicativo di questa tecnologia e dove viene più spesso utilizzata? Scopriamolo insieme in questa puntata di Le Voci dell’AI.
La colorazione automatica delle immagini in bianco e nero è un compito affascinante e complesso, dell’elaborazione delle immagini digitali.
In un’immagine in scala di grigi tutte le informazioni cromatiche originarie sono completamente assenti. Rimane solo la luminosità distribuita lungo una scala continua tra il nero e il bianco.
Questo implica che, a differenza di altri compiti di restauro, colorare un’immagine non significa semplicemente ripristinare dei dati mancanti, ma immaginare e generare nuove informazioni, ovvero inventare i colori plausibili che avrebbero potuto esserci.
Il problema si fonda su una forte componente di ambiguità. Lo stesso valore di grigio può corrispondere a moltissimi colori diversi della realtà. Per esempio, un vestito grigio potrebbe essere originariamente rosso, oppure blu o verde. La scelta del colore corretto dipende dal contesto visivo e da ciò che sappiamo del mondo.
Per affrontare questa sfida, i primi approcci automatici utilizzavano regole basate su caratteristiche locali dell’immagine, come bordi o tessiture, per assegnare colori approssimativi, spesso copiandolo da immagini simili già colorate.
Tuttavia, questi metodi erano limitati e spesso producevano risultati poco dettagliati o incoerenti.
L’introduzione dell’apprendimento automatico delle reti neurali convoluzionali, CNN, ha segnato una svolta importante in questo contesto.
Grazie alla loro capacità di apprendere rappresentazioni gerarchiche contestuali delle immagini, le CNN hanno permesso di generare colorazioni più realistiche, tenendo conto della struttura globale della scena.
Successivamente l’avvento dei Transformers, modelli originariamente sviluppati per il linguaggio naturale ma poi adattati anche alla visione artificiale, ha permesso un ulteriore salto di qualità.
Grazie ai meccanismi di attenzione che abbiamo raccontato più volte in questa rubrica, i Transformers riescono a cogliere relazioni più complesse tra le varie parti dell’immagine, portando a una colorazione più coerente e raffinata.
Oggi i modelli più avanzati combinano la visione artificiale con la comprensione del linguaggio naturale.
I Vision Language Models sono in grado non solo di analizzare forme, e strutture visive per la colorazione, ma anche di interpretare indicazioni testuali, permettendo quindi una colorazione guidata semanticamente.
Ad esempio, è possibile chiedere al modello di colorare un vestito rosso o un cielo al tramonto, integrando l’intuizione visiva con l’interpretazione linguistica.
In questo modo la colorazione automatica diventa non solo un processo probabilistico, ma anche comunicativo e interattivo, capace di riflettere l’immaginazione umana.
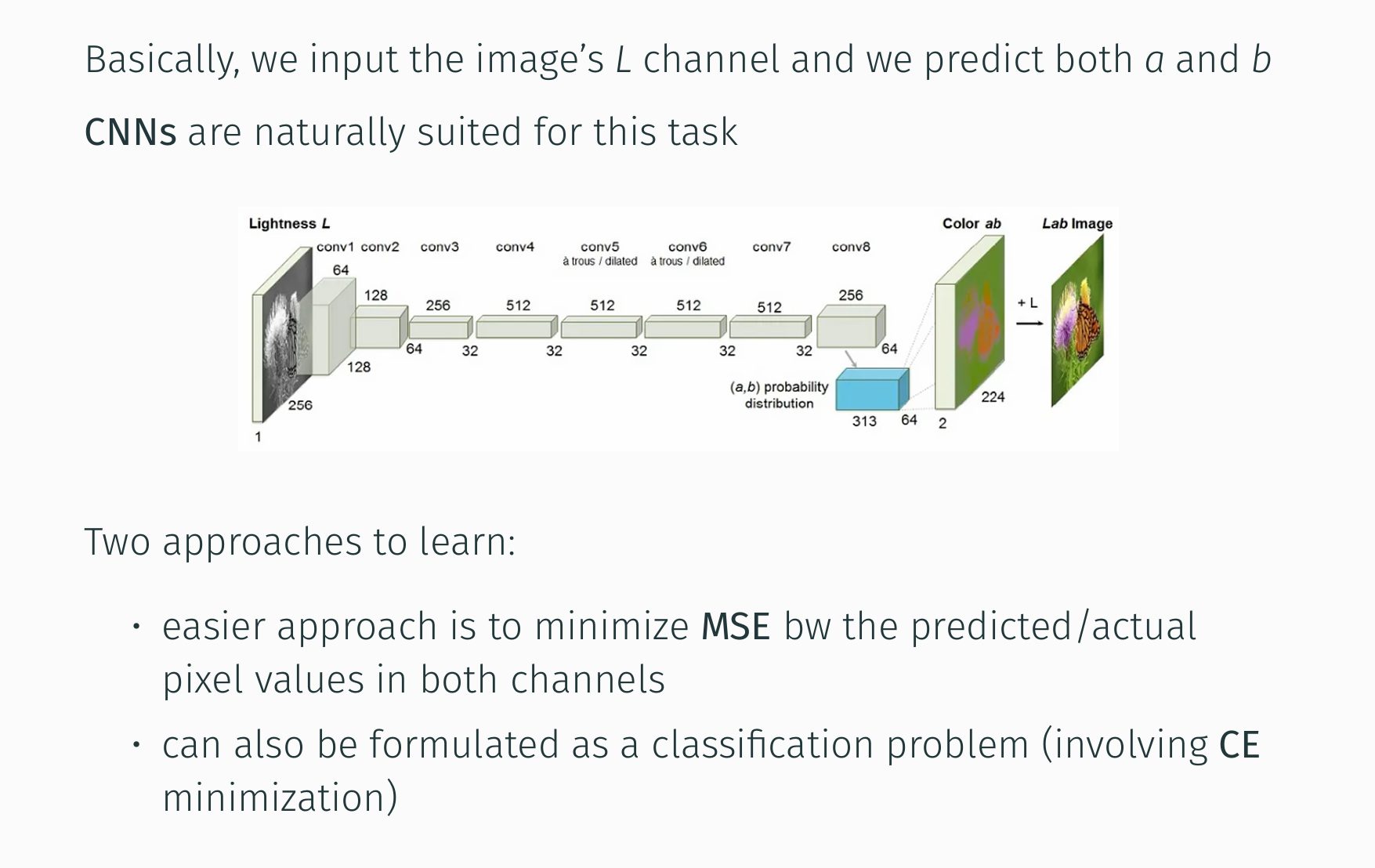
In questa immagine vediamo un approccio classico basato su una rete a convoluzione per la colorazione automatica.
Il processo inizia con l’input del canale di luminanza L di un’immagine in scala di grigi.
Questa informazione di intensità viene quindi processata attraverso una serie di livelli computazionale da conv1 a conv8.
Ogni strato applica filtri, sostanzialmente, per estrarre caratteristiche gerarchiche dall’immagine in ingresso, con un aumento e successiva diminuzione del numero di canali indicati dai numeri sotto i blocchi funzionali e una riduzione della dimensione spaziale delle immagini.
La rete neurale mira a predire i due canali di crominanza a e b nello spazio colore chiamato Lab, modo di rappresentare l’immagine digitale a colori.
Essi rappresentano rispettivamente le componenti verde/magenta e blu/giallo, quelle di colore.
L’output della CNN è sostanzialmente una mappa di probabilità ab, che viene poi combinata con il canale L originale per ricostruire le immagini a colori.
Per addestrare questa rete neurale vengono presentate coppie di immagini a colori e le loro corrispondenti versioni in scala di grigi, solo il canale L di input.
L’obiettivo è minimizzare la differenza tra i valori dei canali a e b predetti, quelli che ci inventiamo e i valori effettivi dei canali a e b dell’immagine a colori originale. Questo ci consente poi di colorare nuove immagini mai viste prima in scala di grigi.
Come si fa a definire il processo di addestramento? In due modi principali.
Minimizzando l’errore quadratico medio: in questo approccio si confronta direttamente i valori dei pixel predetti con quelli reali dei canali a e b, penalizzando le grandi discrepanze, oppure formulando il problema come uno di classificazione invece di predire direttamente i valori a e b per ogni pixel.
Questo approccio discretizza lo spazio colore a e b in un numero finito di classi.
Poi la rete viene addestrata a classificare ogni pixel in una di queste classi di colore, misurando la discrepanza tra la distribuzione proprietà predetta e la classe di valore effettivo.
Quindi, entrambi gli approcci consentono alla CNN di apprendere una mappatura complessa tra le informazioni di luminanza e le informazioni di colore, permettendo di colorare automaticamente nuove immagini in scala di grigi.
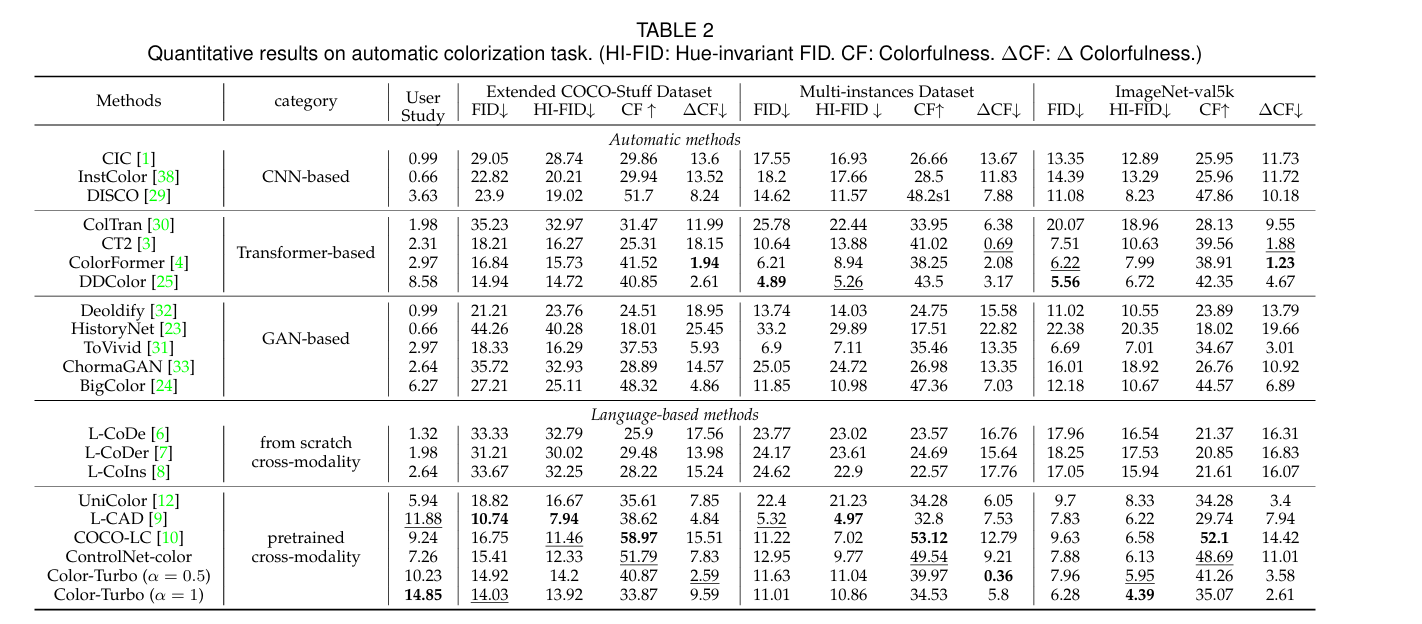
In questa immagine vediamo invece una tabella comparativa di diversi metodi per la colorazione automatica estesa, valutati su vari dataset: Extended COCO-Stuff Dataset, Multi-instances Dataset, ImageNet-val5k e con diverse metriche classiche di differenza tra immagini a colori.
I metodi confrontati sono raggruppati per architettura: CNN, Transformers, GAN e Large Language Models.
Le metriche di valutazione includono FID – Fréchet Inception Distance per la qualità percettiva, HI-FID, una variante di FID relativa alla invarianza sulla tonalità, la colorfulness e il cambiamento di colore. In generale valori più bassi per FID e HI-FID indicano una migliore qualità percettiva dell’immagine, una maggiore somiglianza con la distribuzione dei colori delle immagini reali, mentre valori più alti di X indicano una maggiore vivacità dei colori.
Analizzando i risultati si osserva una certa variabilità nelle prestazioni dei diversi approcci a seconda dei target.
Quindi, come al solito, non esiste un’unica soluzione per qualsiasi problema di colorazione.
Tuttavia, emergono alcune tendenze. I metodi basati su Transformers come Coltran e ColorFormer tendono a mostrare risultati competitivi, spesso superando i metodi basati sulla CNN in termini di FID e HI-FID, suggerendo quindi una migliore qualità percettiva e coerenza cromatica.
I metodi basati su GAN mostrano anch’essi buone performance in alcuni casi, ma è particolarmente interessante notare le performance dei metodi language-based più moderni che sfruttano questi modelli linguistici di grandi dimensioni e potenzialmente Vision Language Models.
Alcuni di questi approcci, specialmente quelli pretrained come ControlNet-color, raggiungono risultati notevoli, spesso con i valori FID e HI-FID più bassi, indicando una qualità di colore superiore.
Questo suggerisce che l’integrazione di una comprensione semantica appresa da grandi quantità di testo e immagini può guidare una colorazione più accurata e contestualmente rilevante.
Quindi, sebbene le Convolutional Neural Networks abbiano rappresentato un approccio fondamentale classico per la colorazione automatica, i risultati presentati in questa tabella evidenziano come le architetture più moderne, che spesso incorporano meccanismi di attenzione tipici dei Transformers e sfruttino la conoscenza appresa da Large Vision Models, abbiano il potenziale per raggiungere prestazioni significativamente migliori in termini di qualità percettiva e accuratezza della colorazione.
Bene, in questa puntata abbiamo discusso di colorazione automatica, un compito di visione artificiale molto interessante da un punto di vista scientifico e artistico.
Queste soluzioni sono spesso utilizzate per la colorazione di video d’epoca originariamente catturati in scala di grigi o per migliorare gli aspetti di colorazione e fotografia in post-produzione, mantenendo realisticità e controllo sull’immagine.
Con l’avvento dei modelli multimodali per la colorazione di video e immagini, non possiamo che aspettarci nel futuro una qualità e un controllo della colorazione sempre più granulare, oltre che all’integrazione di questi strumenti nei servizi e prodotti che usiamo ogni giorno negli ambienti più svariati.
Ciao! Alla prossima puntata di Le Voci dell’AI!