

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco, ricercatore e docente all’Università di Pisa.
Nella puntata di oggi torniamo a parlare di visione artificiale, dopo tante puntate sull’elaborazione del linguaggio naturale, l’interesse nei Large Language Models di questi tempi.
Parliamo in particolare di un compito molto tradizionale, ma tuttora fondamentale e utilissimo a livello applicativo, ossia l’object detection.
Come rilevare all’interno di un’immagine la posizione e l’identità di uno o più oggetti di interesse? Quali sono le metodologie allo stato dell’arte in questa direzione? Si tratta di soluzioni efficienti che possono essere utilizzate per ogni scopo applicativo e possono funzionare su ogni tipologia di hardware.
Scopriamolo insieme in questa puntata di Le Voci dell’AI.
L’Object Detection è uno dei compiti fondamentali nel campo dell’intelligenza artificiale applicata alla visione artificiale e consiste non solo nell’identificare cosa è presente in un’immagine, come fa l’object recognition, ma anche dove si trova disegnando un riquadro attorno agli oggetti riconosciuti.
Questo compito o task ha una valenza storica molto importante.
Prima ancora dell’avvento del deep learning si affrontava con tecniche classiche come i filtri di Haar o i metodi basati sull’estrazione di caratteristiche con metodi manuali che richiedevano una profonda competenza di dominio e non garantivano la flessibilità nell’efficacia dei sistemi moderni.
Con l’avvento delle Convolutional Neural Networks, le reti a convoluzione, il panorama è cambiato radicalmente.
Oggi i modelli basati su CNN, come la celebre famiglia YOLO, You Only Look Once, dominano il settore per la loro velocità e precisione.
Accanto a questi tecniche più recenti basate su architetture Transformers come Detr, Detection Transformer, stanno emergendo offrendo un approccio innovativo e alternativo più vicino ai modelli di linguaggio che visivi, ma ancora relativamente pesante in termini computazionali.
In questa puntata ci concentriamo su YOLO perché rimane, nonostante gli anni, la scelta più pratica e diffusa ingegnerizzata per applicazioni che richiedono real time object detection, come la guida autonoma e i sistemi di sicurezza intelligenti.
Grazie a una progettazione attenta dal punto di vista sia software sia hardware, YOLO permette di eseguire il rilevamento direttamente At the Edge, quindi sul dispositivo stesso, localmente come su droni, telecamere, automobili, senza il bisogno di inviare i dati a server remoti nel cloud: un vantaggio decisivo per ridurre la latenza, aumentare la privacy e garantire un’operatività immediata anche in assenza di una connessione internet.
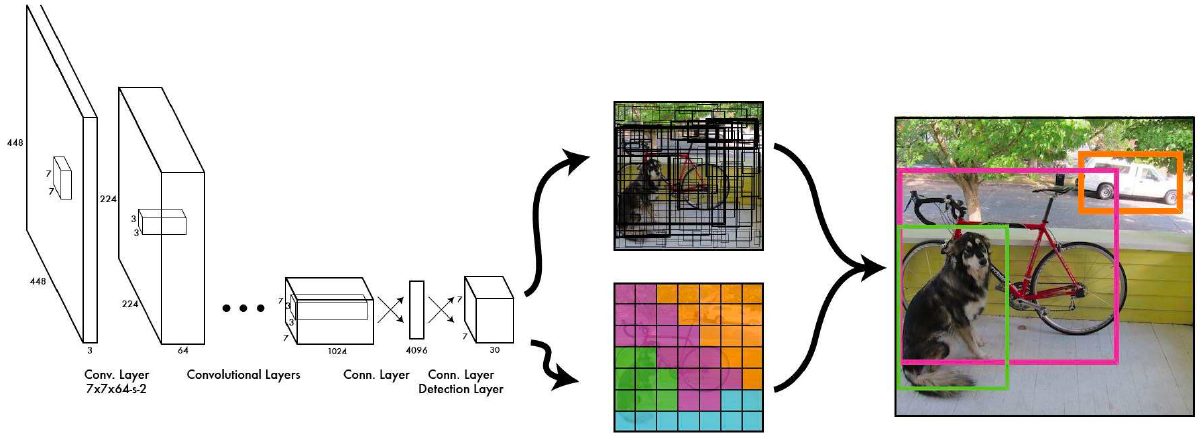
In questa immagine vediamo il design e funzionamento di YOLO, decisamente uno dei modelli più celebri per l’object detection.
L’idea chiave è di trattare l’intera immagine come un unico problema di regressione, prevedendo direttamente le classi e i riquadri di oggetti in un solo passaggio, quindi senza il bisogno di individuare prima le possibili regioni di interesse.
Da qui il nome celebre You Only Look Once, relativo al guardare una sola volta l’immagine per decretare la presenza di più oggetti simultaneamente.
Il processo inizia quindi applicando una serie di convoluzioni, ovvero operazioni che estraggono in maniera gerarchica caratteristiche locali da piccoli blocchi dell’immagine.
L’immagine viene poi suddivisa in una griglia e ogni cella della griglia è responsabile a livello intuitivo della rilevazione degli oggetti che hanno il centro al suo interno.
Per ogni cella il modello quindi predice le coordinate dei riquadri, bounding boxes, la probabilità di presenza di un oggetto e la relativa classe.
Dopo una fase di elaborazione e filtraggio dei riquadri più sovrapposti, otteniamo le previsioni finali, come si vede nell’ultimo riquadro a destra.
Questo approccio, basato quindi su convoluzioni, il blocco computazionale fondamentale di questa soluzione consente loro di essere estremamente veloce, rendendolo ideale per applicazioni in tempo reale, dove rapidità e precisione sono essenziali.
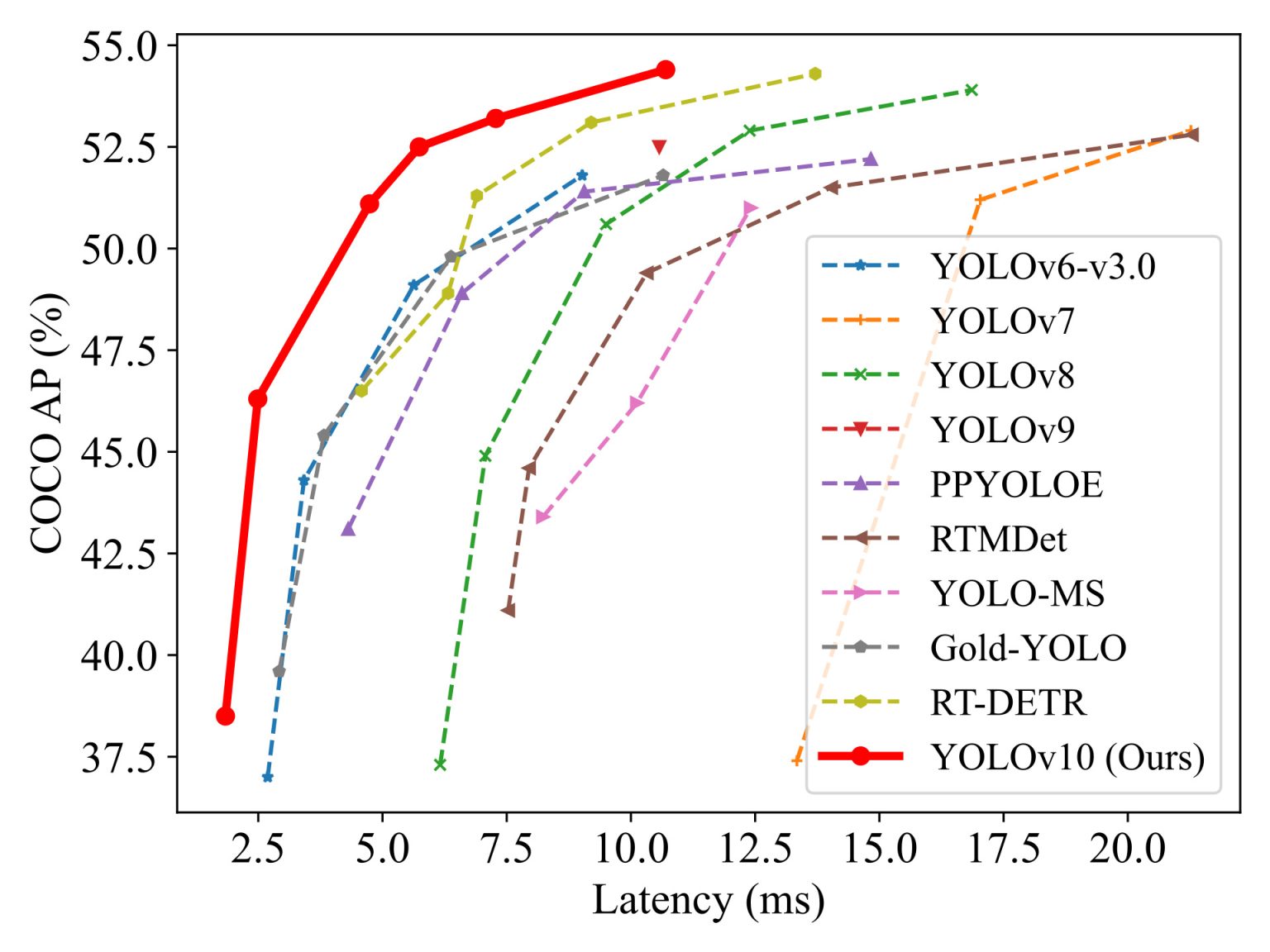
Questo grafico confronta invece le prestazioni di diversi modelli di object detection in termini di accuratezza, l’asse verticale su un dataset, un benchmark di riferimento, Coco e la latenza sull’asse orizzontale in millisecondi.
Quanto è veloce nella predizione ogni metodo? Idealmente vogliamo dei modelli più possibile in alto a sinistra, cioè più precisi e veloci.
La linea rossa rappresenta YOLOv10 in una ingegnerizzazione specifica, una delle ultime evoluzioni della famiglia YOLO, e mostra chiaramente un netto miglioramento rispetto agli altri modelli, raggiungendo una combinazione migliore di accuratezza e velocità.
In particolare, YOLOv10 supera non solo le versioni precedenti Yolo 7,8,9, ma anche altri concorrenti più recenti come PPYOLOE, RTMDet, e persino RT-DETR che abbiamo menzionato prima, basato su Transformers, mantenendo una latenza piuttosto bassa.
Questo significa che YOLOv10 riesce a rilevare gli oggetti all’interno delle nostre immagini in modo molto preciso, senza sacrificare la rapidità, un aspetto cruciale per applicazioni real time, come dicevamo, e per il mondo dell’IoT, l’edge computing, come la guida autonoma o la videosorveglianza.
Il grafico evidenzia quindi come l’ingegnerizzazione dietro YOLO, specialmente in questo susseguirsi di soluzioni via via migliore, rappresenti attualmente un perfetto equilibrio tra efficienza e prestazioni.
Ecco la scelta tra modelli come YOLO ed RT-DETR dipende fortemente dall’hardware disponibile e dal tipo di problema che volete risolvere.
Se si dispone di acceleratori ottimizzati per CNN, quindi per convoluzione come software che gira su GPU o chip specializzati presenti in molte piattaforme edge YOLO è quasi sempre la scelta migliore.
Grazie alla sua struttura computazionale compatta, infatti estremamente veloce, efficiente e facile da integrare in sistemi che richiedono rilevamenti in tempo reale.
Al contrario, RT-DETR basandosi su architetture Transformers, offre una maggiore capacità di modellare relazioni complesse tra oggetti nell’immagine e tende ad essere usato in scenari dove la qualità della predizione è più importante della latenza, come nel processamento di immagini offline o in data center.
Tuttavia, i modelli Transformers richiedono hardware più pesante e generalmente meno adatto, meno ottimizzato per il calcolo edge.
In sintesi, se l’obiettivo è ottenere la massima velocità, semplicità di deploy e bassa latenza, YOLO rimane imbattibile a mio giudizio.
Se invece si ha accesso a risorse di calcolo abbondanti e si cerca una precisione più alta, l’identificazione anche dell’area di interesse in immagini complesse RT-DETR, può essere una valida alternativa.
Bene, in questa puntata abbiamo parlato di object detection, ormai una comodità nel mondo dell’AI, data la sua disponibilità in servizi e prodotti commerciali sempre più numerosi, ma anche per la sua robustezza ed affidabilità.
Questo è stato reso possibile grazie all’architettura YOLO, che ha democratizzato il suo utilizzo in ogni ambito, da edge a cloud con risultati incredibili.
Oggi siamo spettatori, dopo tanti anni di predominio assoluto all’avvento dei Transformers, che mettono finalmente in seria discussione questo primato di YOLO.
Nella prossima puntata vedremo meglio come è possibile, tramite questa architettura moderna alla base dei Large Language Models, implementare un sistema di rilevamento di oggetti competitivi.
Ma per adesso gustiamoci la solidità e bellezza di YOLO, ormai arrivato alla sua undicesima versione.
Ciao! Alla prossima puntata di Le Voci dell’AI!