

{kind=link}
Ciao a tutti, sono Vincenzo Lomonaco, ricercatore e docente all’Università di Pisa.
Nellla puntata di oggi parleremo del recente rilascio dell’attesissimo modello open source di Meta AI, Llama 4 e delle incredibili novità tecnologiche che esso introduce.
Si tratta davvero di un salto in avanti in termini di qualità rispetto ai modelli attualmente in voga? Cosa aspettarci nel futuro prossimo in termini di modelli open source che potremo comodamente personalizzare per prodotti e servizi più specifici? Scopriamolo insieme in questa puntata di Le Voci dell’AI.
Meta ha recentemente annunciato il rilascio di Llama 4, l’ultima evoluzione della sua famiglia di modelli linguistici di grandi dimensioni.
A differenza delle versioni precedenti, la 4 non consiste in realtà in un singolo modello, ma in tre varianti distinte: Scout, Maverick e Behemoth, tutte e tre basate su una tecnologia mistura di esperti.
Vedremo in seguito di cosa si tratta.
Scout è il più compatto, il più piccino, con 17 miliardi di parametri attivi durante l’inferenza e 16 esperti, per un totale di 109 miliardi di parametri.
Maverick, più potente, mantiene 17 miliardi di parametri attivi durante il suo utilizzo, ma incorpora 128 esperti per un totale di 400 miliardi di parametri.
Infine, Behemoth rappresenta il modello più gigantesco, grande, avanzato, con 288 miliardi di parametri attivi distribuiti su 16 esperti e un impressionante totale di 2 trilioni di parametri.
Attualmente Scout e Maverick sono disponibili al pubblico e già scaricabili, mentre Behemoth è ancora in fase di addestramento e in preview in questo momento.
Questa nuova architettura, basata su Mixture of Experts, come dicevamo, conferisce a LLama 4 capacità multimodali avanzate native, dice Meta AI, permettendo l’elaborazione simultanea di testo e immagini.
Inoltre, offre una finestra di contesto di input incredibilmente vasta con Scout, in particolare, che supporta fino a 10 milioni di token, rendendolo di fatto il modello open source più avanzato in tal senso.
Il rilascio di Llama 4 segna in generale sicuramente un passo significativo nell’evoluzione dell’AI multimodale, offrendo agli sviluppatori e ai ricercatori un punto di partenza, un modello open source estremamente interessante dal punto di vista sia dell’efficacia sia dell’efficienza.
Ma approfondiamo insieme questi aspetti metodologici particolarmente interessanti.
Che cos’è questa Mixture of Experts, questa mistura di esperti? La tecnica Mixture of Experts, MOE in breve, si sta affermando come una componente chiave nei modelli AI all’avanguardia, anche Deepseek, per esempio la utilizza.
A differenza dei modelli tradizionali che attivavano tutti i parametri del modello durante il loro utilizzo, a ogni inferenza un MOE attiva solo una piccola parte del modello, un sottoinsieme di esperti per ogni input.
Questo approccio consente una scalabilità molto più efficiente.
È possibile costruire modelli con trilioni di parametri durante l’addestramento, ma mantenere un costo computazionale gestibile durante l’inferenza, durante il loro utilizzo.
In LLama 4, ad esempio, solo due esperti vengono attivati per ciascun token, il che permette di mantenere l’efficienza computazionale di un modello magari da 17 miliardi di parametri, pur beneficiando della capacità di un modello con centinaia di miliardi di parametri in totale.
Questa strategia non solo migliora le performance in compiti complessi, ma favorisce anche una specializzazione interna durante l’addestramento, in cui diversi esperti possono concentrarsi su diversi tipi di input o sottoproblemi.
In un contesto quindi in cui i modelli devono gestire input multimodali, contesti molto lunghi e richieste sempre più complesse di ragionamento, il Mixture of Experts Model rappresenta una risposta elegante e potente al dilemma della scalabilità.
Proprio per questo si sta consolidando come una tecnologia indispensabile nei modelli di frontiera di intelligenza artificiale.
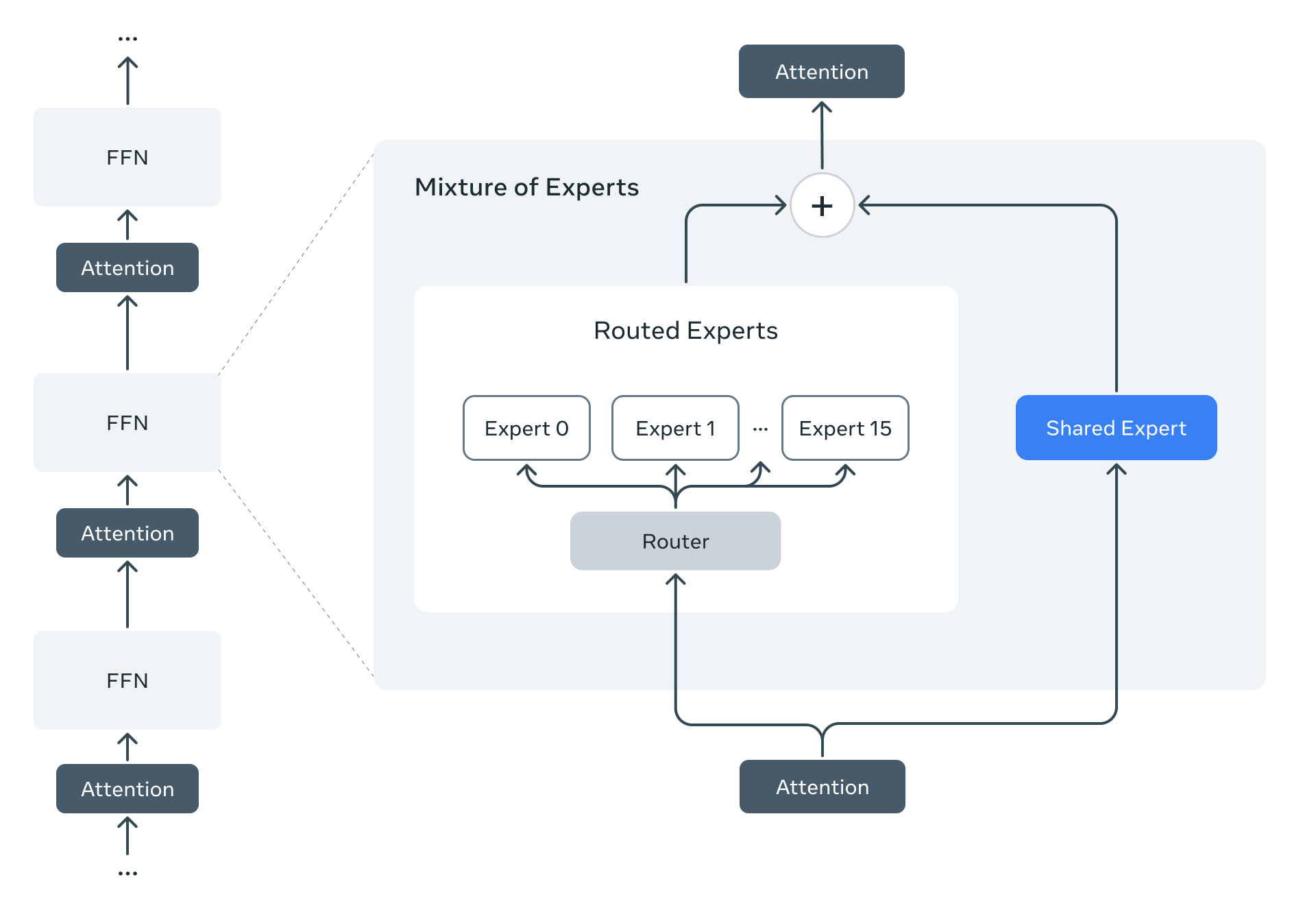
In questa immagine vediamo l’architettura di un modello Transformer potenziato con un blocco Mixture of Experts, MOE.
A sinistra si vede una sequenza di blocchi Transformer standard, alternando strati di Attention, autoattenzione e FFN Fit Forward Network; a destra invece il blocco Feed Forward Network viene sostituito da un modulo, per l’appunto MOE e questo modulo è composto da un router che, basandosi su l’input proveniente dallo strato d’attenzione precedente, decide quali expert, alla fine reti neurali specializzate elaboreranno tale input e l’immagine mostra un esempio con 16 esperti differenti.
Inoltre notiamo anche la presenza di uno Shared Expert che elabora l’input in parallelo agli esperti selezionati.
Le uscite degli esperti selezionati e dello Shared Expert vengono poi aggregate tramite una somma pesata e il risultato viene passato attraverso un ulteriore strato d’attenzione prima di procedere al blocco successivo del Transformer.
Questa architettura Mixture of Experts consente al modello di aumentare quindi le sue capacità in modo efficiente, attivando solo una parte dei suoi parametri per ogni input, migliorando quindi, come dicevamo, la scalabilità e le prestazioni generali di questa soluzione.
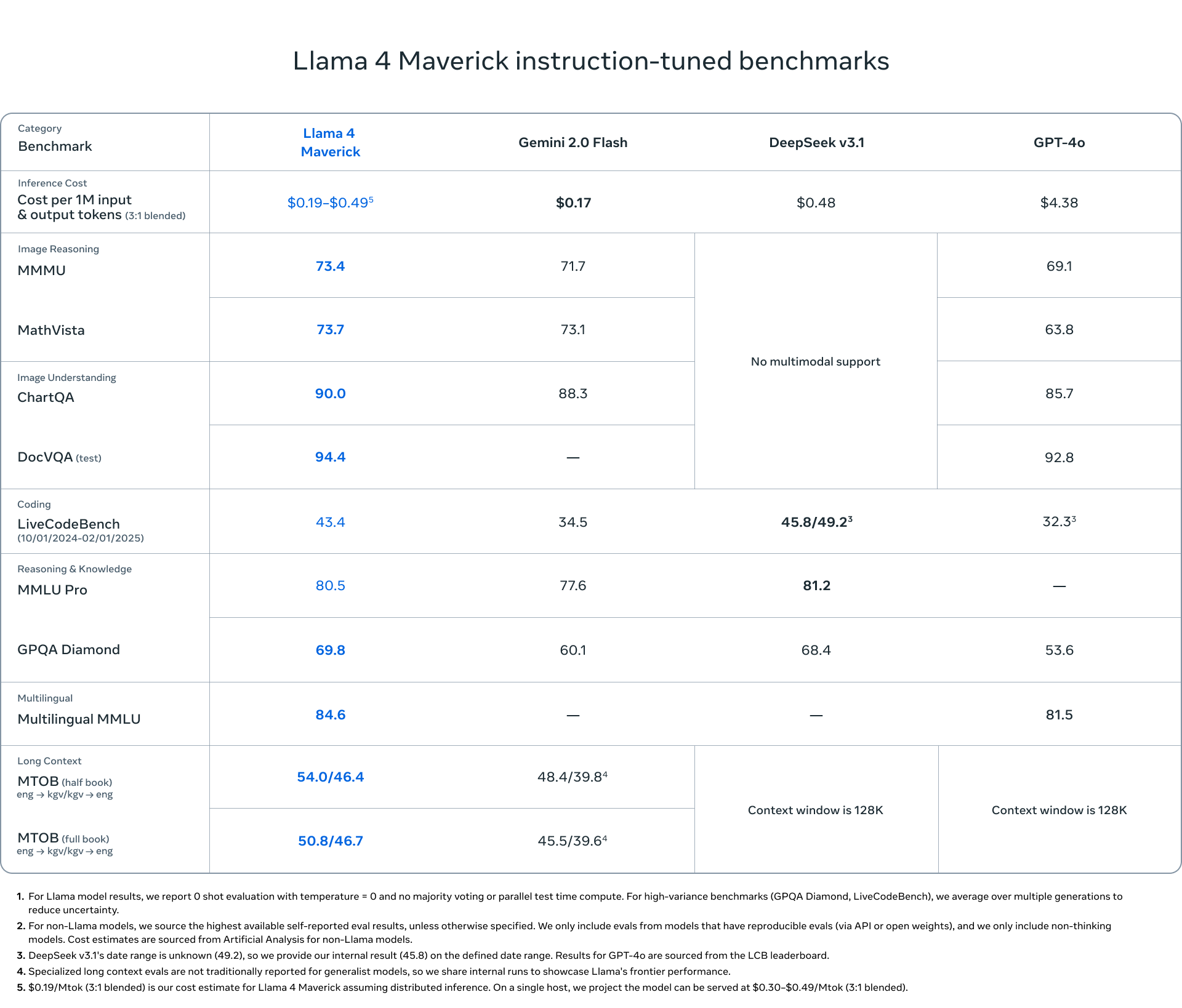
Questa immagine invece, confronta le prestazioni del modello linguistico LLama 4 Maverick.
Potete consultare anche il blog post ufficiale di Meta per saperne di più circa le performance degli altri due modelli della gamma Llama e vediamo come questo modello Maverick successivamente raffinato su compiti specifici si comporti con altri modelli di spicco come Gemini 2.0 Flash, Deepseek versione 3.1 e GPT-4o.
La tabella quindi valuta questi modelli in diverse categorie, tra cui il costo di inferenza per token di input e output e il ragionamento sulle immagini, la comprensione delle immagini, lo sviluppo software, il recupero della coscienza e le capacità di ragionamento, la capacità di gestire più lingue, la gestione di contesti lunghi, per esempio nella traduzione di libri interi da una lingua all’altra, tutta una serie di compiti valutati su diversi benchmark di riferimento.
Llama 4 Maverick nei risultati mostra generalmente prestazioni molto competitive che spesso superano Gemini 2.0 Flash praticamente sempre anche GTP-4o a una frazione irrisoria del costo.
Gli unici compiti dove Deepseek sembra eccellere sono il coding e il ragionamento.
L’analisi dei costi comunque suggerisce che Llama 4 Maverick offre un equilibrio favorevole tra prestazioni e costo di inferenza rispetto ai competitors più in voga.
Prima di concludere questa puntata ci tenevo anche a sottolineare le capacità, specialmente di Scout, di gestire un contesto di input esteso.
Esso è misurato in tokens, numero di tokens ed è cruciale per i modelli linguistici di grandi dimensioni perché gli permette di elaborare e comprendere informazioni più ampie e complesse in una singola iterazione.
Un contesto maggiore consente al modello di attingere a una base di conoscenza più vasta e di mantenere la coerenza attenzione su testi più lunghi e conversazioni su più turni, migliorando la qualità delle risposte e la capacità di seguire istruzioni dettagliate.
L’affermazione che Llama 4 Scout vanta una finestra di contesto di 10 milioni di token solleva interessanti interrogativi sull’utilità futura di tecniche come il Rag ed il fine tuning introdotti nell’episodio 55 e 63 di Le Voci dell’AI, rispettivamente.
RAG mira a superare i limiti della finestra del contesto, recuperando informazioni esterne rilevanti, mentre il fine tuning adatta un modello a compiti specifici con dei dati più mirati.
Se un modello può nativamente processare un volume di informazioni così vasto e per inciso, basti pensare che l’intera Wikipedia in inglese ammonta a circa 2 milioni di tokens, la necessità di integrare conoscenza estesa tramite Rag o di specializzare il modello tramite estensioni potrebbe potenzialmente diminuire o addirittura scomparire per alcune applicazioni.
Bene, in questa puntata abbiamo discusso del recente rilascio di Llama 4 come un vero e proprio ecosistema di modelli open source, supportato dal team di Meta AI.
Si tratta di una chiara strategia da parte di Meta volta alla creazione di una comunità attorno all’utilizzo di questi modelli e strumenti, servizi e prodotti commerciali annessi.
Si tratta forse del nuovo Android? di un progetto open source che aprirà la strada ad un nuovo mercato aperto per soluzioni di AI sempre più avanzate? Nessuno lo sa, ma per adesso godiamoci questi modelli liberamente accessibili ed utilizzabili da tutti.
Ciao! Alla prossima puntata di Le Voci dell’AI!