


{kind=link}
Dallo Spark + AI Summit, trasformato quest’anno in evento virtuale per i data team di tutto il mondo, arriva l’annuncio che MLflow, piattaforma di machine learning open source creata da Databricks, entrerà a far parte della Linux Foundation.
Circa due anni fa Databricks aveva lanciato MLflow, una piattaforma di apprendimento automatico end-to-end open source, progettata per consentire ai team di costruire e mettere in produzione in modo affidabile applicazioni di machine learning.
Da allora, ha sottolineato Databricks, la piattaforma ha conosciuto un’enorme adozione da parte della community legata alla data science, con oltre 2,5 milioni di download mensili, 200 contributor provenienti da 100 organizzazioni e una crescita 4x su base annua.
In sintesi, MLflow è diventata la piattaforma di machine learning open source più utilizzata, dimostrando, evidenzia ancora Databricks, i vantaggi di una open platform per gestire lo sviluppo di machine learning che funzioni su librerie, linguaggi e ambienti cloud e on-premise diversi.
MLflow si “trasferisce” nella Linux Foundation in modo che quest’ultima, quale organizzazione no profit indipendente dal fornitore, possa gestire il progetto sul lungo termine. Ciò dovrebbe portare ancora più contributi, e quindi un ulteriore sviluppo, a MLflow.
Tuttavia, ciò non significa che Databricks intenda disimpegnarsi dalla piattaforma, anzi, tutt’altro: l’azienda ha affermato di voler intensificare ulteriormente il suo investimento in MLflow e, sempre allo Spark + AI Summit, ha annunciato tre aspetti su cui si sta impegnando per semplificare ulteriormente il lifecycle del machine learning: autologging, governance del modello e deployment del modello.
Una delle maggiori sfide che devono affrontare i professionisti dell’apprendimento automatico è come tenere traccia dei set di dati intermedi utilizzati durante l’addestramento dei modelli. Per questo motivo in MLflow 1.8 è stato introdotto l’autologging per le origini dati Apache Spark, il primo passo verso il data versioning con MLflow.
Attualmente l’autologging supporta sei librerie: TensorFlow, Keras, Gluon, LightGBM, XGBoost e Spark. Ci sono anche lavori in corso da parte di Facebook per aggiungere presto il supporto per PyTorch e da parte di Databricks per aggiungere il supporto per scikit-learn.
Per gli utenti della piattaforma Databricks, l’azienda sta anche lavorando per integrare l’autologging con le funzionalità di gestione dei cluster e dell’environment in Databricks.
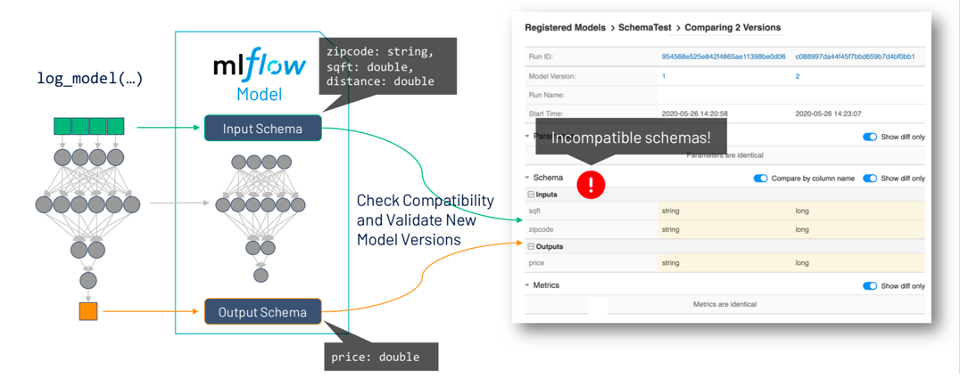
Per quanto riguarda la model governance, uno dei punti dolenti più comuni nel deployment dei modelli, sottolinea Databricks, è assicurarsi che lo schema per i dati di produzione utilizzati per assegnare un punteggio ai modelli sia compatibile con lo schema dei dati utilizzati durante il training del modello, e che l’output da una nuova versione del modello sia quello che ci si aspetta in produzione.
Pertanto, gli sviluppatori della piattaforma stanno estendendo il formato del modello MLflow per includere il supporto per i model schema, che memorizzeranno le caratteristiche e i requisiti di previsione per i modelli (nomi di input e output e tipi di dati).
Una delle cause più comuni di interruzioni della produzione nel machine learning è una mancata corrispondenza degli schemi del modello quando ne viene distribuito uno nuovo. Con l’integrazione del model schema e del model registry, MLflow consentirà di confrontare le versioni del modello e i loro schemi e avviserà l’utente se ci sono incompatibilità.
Infine, il deployment. MLflow dispone già di integrazioni con diverse opzioni di distribuzione del modello, tra cui piattaforme di serving batch o in tempo reale. L’intenzione è ora di fornire alla community un’API più semplice per gestire il deployment del modello.
La nuova API Deployments per la gestione e la creazione di endpoint di distribuzione fornirà gli stessi comandi per il deployment in numerosi ambienti, eliminando la necessità di scrivere codice personalizzato per le specifiche individuali di ciascuno.
È già in uso per sviluppare due nuovi endpoint per RedisAI e Google Cloud Platform e Databricks ha informato di essere al lavoro sul porting di molte delle passate integrazioni (tra cui Kubernetes, SageMaker e AzureML) su questa API. Ciò offrirà agli utenti un modo semplice e uniforme per gestire le distribuzioni e per il push dei modelli su diverse piattaforme di serving, secondo le necessità.