


Il riconoscimento della scrittura a mano libera non è un novità per la piattaforma Google, e con Gboard fa un ulteriore passo avanti.
Nel 2015 Big G lanciava Google Scrittura a mano libera. La tastiera consentiva agli utenti di scrivere a mano il testo sul proprio dispositivo mobile Android. Al momento del lancio iniziale erano supportate 82 lingue.
L’anno scorso Google ha aggiunto a Gboard per Android il supporto per il riconoscimento della grafia in più di 100 lingue. Gboard è la tastiera di Google per dispositivi mobili che offre varie tipologie di input, tra cui la scrittura a mano libera.
Dalle prime implementazioni, informa ora Google, il progresso nel machine learning ha abilitato nuove architetture di modelli e metodologie di training. Ciò ha permesso di rivedere l’approccio iniziale dell’azienda. E di costruire, al suo posto, un singolo modello di apprendimento automatico che funzioni sull’intero input. E che riduce i tassi di errore in maniera sostanziale rispetto alla vecchia versione.
Google ha lanciato questi nuovi modelli per tutti i linguaggi basati sullo script latino in Gboard all’inizio dell’anno.
Dal tratto alle curve di Bézier
Il punto di partenza per qualsiasi sistema di riconoscimento della scrittura a mano online sono i “touch-point”, spiega Google. L’input disegnato viene rappresentato come una sequenza di tratti. Ognuno di questi tratti, a sua volta, è una sequenza di punti, ciascuno con un timestamp associato.
Siccome Gboard viene utilizzato su un’ampia varietà di dispositivi e risoluzioni dello schermo, il primo passo è quello di normalizzare le coordinate del touch-point. Per catturare accuratamente la forma, la sequenza di punti è poi convertita in una sequenza di curve di Bézier. Queste sono utilizzate come input per una rete neurale ricorrente (RNN), addestrata per identificare con precisione il carattere che viene scritto.
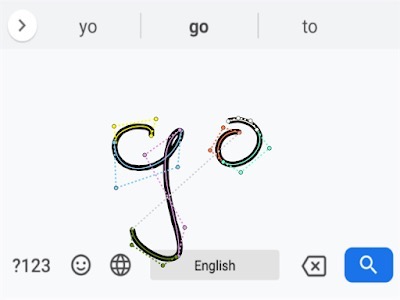 Le curve di Bézier hanno una lunga tradizione di utilizzo nel riconoscimento della scrittura a mano. Tuttavia, sottolinea Google, utilizzarle come input è una novità. Questo metodo consente di fornire una rappresentazione coerente dell’input su dispositivi con frequenze di campionamento e accuratezza differenti.
Le curve di Bézier hanno una lunga tradizione di utilizzo nel riconoscimento della scrittura a mano. Tuttavia, sottolinea Google, utilizzarle come input è una novità. Questo metodo consente di fornire una rappresentazione coerente dell’input su dispositivi con frequenze di campionamento e accuratezza differenti.
Tale metodo differisce significativamente dai precedenti modelli che utilizzavano un approccio cosiddetto segment-and-decode. Quest’ultimo comportava la creazione di diverse ipotesi su come scomporre i tratti in caratteri (segment). Per poi trovare la sequenza di caratteri più probabile da questa scomposizione (decode).
Reti neurali per comprendere la scrittura
Un altro vantaggio di questo metodo è che la sequenza delle curve di Bézier è più compatta della sottostante sequenza dei punti di input. Il che rende più facile per il modello raccogliere le dipendenze temporali insieme all’input. Ogni curva è rappresentata da un polinomio definito da start ed end point, e da due control point aggiuntivi, che determinano la forma della curva.
Per tradurre la sequenza di curve di input negli effettivi caratteri scritti viene usata una RNN multi-layer. Questo passaggio serve a elaborare la sequenza di curve e a produrre una matrice di decodifica di output con una distribuzione di probabilità su tutte le possibili lettere per ogni curva di input.
Il team spiega di aver sperimentato diversi tipi di RNN. Alla fine, Google ha deciso di utilizzare una versione bidirezionale di Quasi-Recurrent Neural Network (QRNN). Le QRNN, spiega ancora Google, alternano tra strati convoluzionali e recurrent. Esse forniscono il potenziale teorico per una efficiente parallelizzazione, oltre a una buona prestazione predittiva.
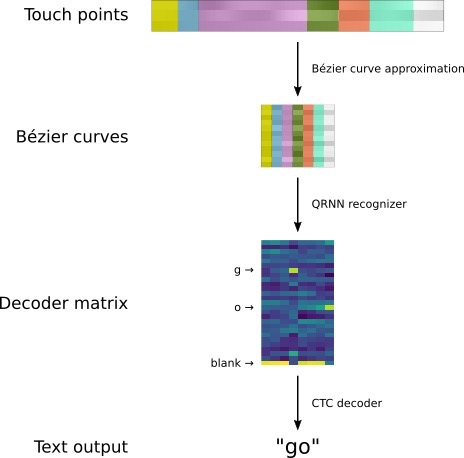 Al fine di “decodificare” le curve, la rete neurale ricorrente produce una matrice. In questa matrice, ogni colonna corrisponde a una curva di input e ogni riga a una lettera dell’alfabeto. La colonna per una curva specifica può essere vista come una distribuzione di probabilità su tutte le lettere dell’alfabeto. Tuttavia, ciascuna lettera può essere costituita da più curve.
Al fine di “decodificare” le curve, la rete neurale ricorrente produce una matrice. In questa matrice, ogni colonna corrisponde a una curva di input e ogni riga a una lettera dell’alfabeto. La colonna per una curva specifica può essere vista come una distribuzione di probabilità su tutte le lettere dell’alfabeto. Tuttavia, ciascuna lettera può essere costituita da più curve.
Questa mancata corrispondenza tra la lunghezza della sequenza di output dalla RNN (che corrisponde sempre al numero di curve di bezier) e il numero effettivo di caratteri che l’input dovrebbe rappresentare, viene risolta aggiungendo un simbolo “blank” speciale per indicare che non viene emesso alcun output per un certa curva.
Un decoder a stati finiti viene utilizzato per combinare gli output della rete neurale con un modello linguistico basato su caratteri. Le sequenze di caratteri che sono comuni in una determinata lingua ricevono un “bonus” e hanno maggiori probabilità di essere in output. Mentre le sequenze meno comuni sono penalizzate.
Dalle reti neurali a Gboard
Nonostante siano significativamente più semplici, i nuovi modelli di riconoscimento dei caratteri di Google fanno tra il 20% e il 40% di errori in meno rispetto ai vecchi. Inoltre, sono anche molto più veloci.
Per fornire la migliore user experience possibile, non sono sufficienti modelli di riconoscimento accurati. Questi devono anche essere veloci. Per ottenere la latenza più bassa possibile in Gboard, Google converte i modelli di riconoscimento addestrati in TensorFlow in modelli TensorFlow Lite.
 Ciò implica quantizzare tutti i pesi durante il training del modello, in modo da usare un byte al posto di quattro. Il che porta a modelli più piccoli e tempi di inferenza inferiori. Inoltre, TensorFlow Lite consente di ridurre le dimensioni dell’APK rispetto all’impiego di un’implementazione completa di TensorFlow.
Ciò implica quantizzare tutti i pesi durante il training del modello, in modo da usare un byte al posto di quattro. Il che porta a modelli più piccoli e tempi di inferenza inferiori. Inoltre, TensorFlow Lite consente di ridurre le dimensioni dell’APK rispetto all’impiego di un’implementazione completa di TensorFlow.
Google ha anche pubblicato un documento che spiega in maggiore dettaglio la ricerca alla base di questa versione. Il documento nella sua interezza è consultabile a questo link.









{kind=link}