


Amazon Web Services ha annunciato la disponibilità generale di Amazon Textract, un servizio fully managed (presentato in anteprima qualche mese fa) che utilizza il machine learning per estrarre automaticamente testo e dati, anche da tabelle e moduli, virtualmente da qualsiasi documento, assicura l’azienda, senza la necessità di una revisione manuale, di impiegare codice personalizzato o di alcuna esperienza nella tecnologia di apprendimento automatico.
Amazon Textract, sottolinea AWS, va oltre il semplice processo di optical character recognition (OCR), per identificare il contenuto dei campi nei moduli, le informazioni memorizzate nelle tabelle e il contesto in cui vengono presentate le informazioni. Ad esempio, spiega l’azienda, per rilevare un nome o un numero di previdenza sociale da un modulo amministrativo oppure lo SKU o la quantità di un prodotto in un magazzino da un report di inventario.

Amazon Textract, informazioni dai documenti
Il testo e i dati estratti mediante Amazon Textract possono poi essere facilmente utilizzati per creare ricerche intelligenti su grandi archivi di documenti, oppure possono essere caricati in un database per l’utilizzo da parte di applicazioni di contabilità e controllo, software di conformità e tanto altro.
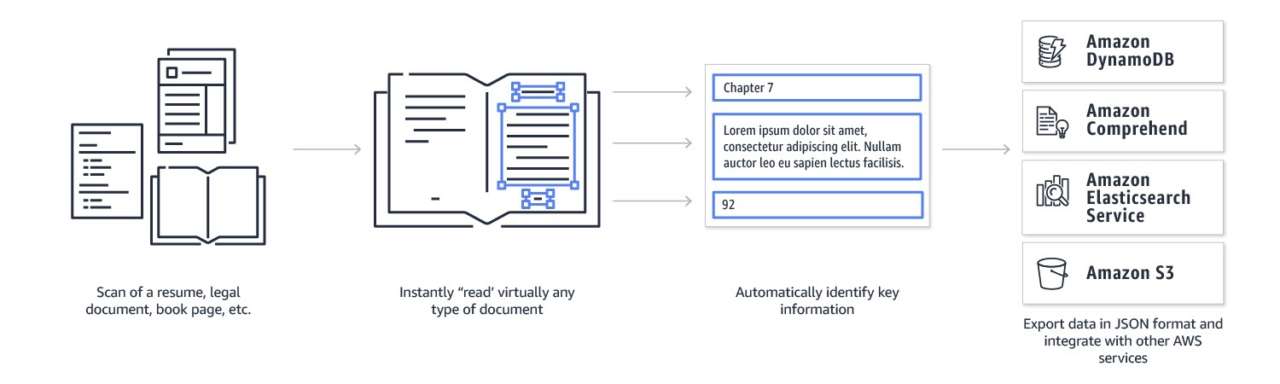 La Api di Amazon Textract supporta formati multipli di immagine, quali scansioni, Pdf e foto, e i clienti possono utilizzarla con servizi di database e analytics come Amazon Elasticsearch Service, Amazon DynamoDB e Amazon Athena. Oppure con altri servizi potenziati dal machine learning, quali Amazon Comprehend, Amazon Comprehend Medical, Amazon Translate e Amazon SageMaker, per ricavare un significato più profondo dal testo e dai dati estratti.
La Api di Amazon Textract supporta formati multipli di immagine, quali scansioni, Pdf e foto, e i clienti possono utilizzarla con servizi di database e analytics come Amazon Elasticsearch Service, Amazon DynamoDB e Amazon Athena. Oppure con altri servizi potenziati dal machine learning, quali Amazon Comprehend, Amazon Comprehend Medical, Amazon Translate e Amazon SageMaker, per ricavare un significato più profondo dal testo e dai dati estratti.
Molte aziende, mette in evidenza Amazon, estraggono testo e dati da fonti quali contratti, note spese, documenti fiscali, moduli di vario genere, attraverso il data entry manuale dei dati o mediante un semplice software OCR. Si tratta di un processo time consuming e spesso impreciso, che produce un output che richiede un’ulteriore gravosa elaborazione, prima di poter essere inserito in un formato utilizzabile da altre applicazioni.
Questo, sostiene Amazon, avviene perché le tecnologie OCR esistenti non sono in grado di riconoscere layout comuni come moduli e tabelle, e generano solo un text dump lungo e spesso impreciso. Ciò di cui le organizzazioni hanno bisogno, e che desiderano, è invece la capacità di identificare ed estrarre con precisione testo e dati da moduli e tabelle in documenti di qualsiasi formato e da una varietà di tipi di file e modelli.
Generare valore dai file
Amazon Textract analizza virtualmente qualsiasi tipo di documento e identifica testo e dati da tabelle e moduli, senza richiedere alcuna personalizzazione o intervento umano. Il sevizio consente alle aziende di elaborare in modo preciso milioni di pagine di documenti in poche ore, riducendo sensibilmente i costi di elaborazione dei documenti e consentendo di concentrarsi sul valore commerciale del testo e dai dati, anziché perdere tempo ed energia nel post-processing. I risultati vengono forniti tramite un’API che può essere facilmente accessibile e utilizzata senza requisiti di esperienza nel machine learning.
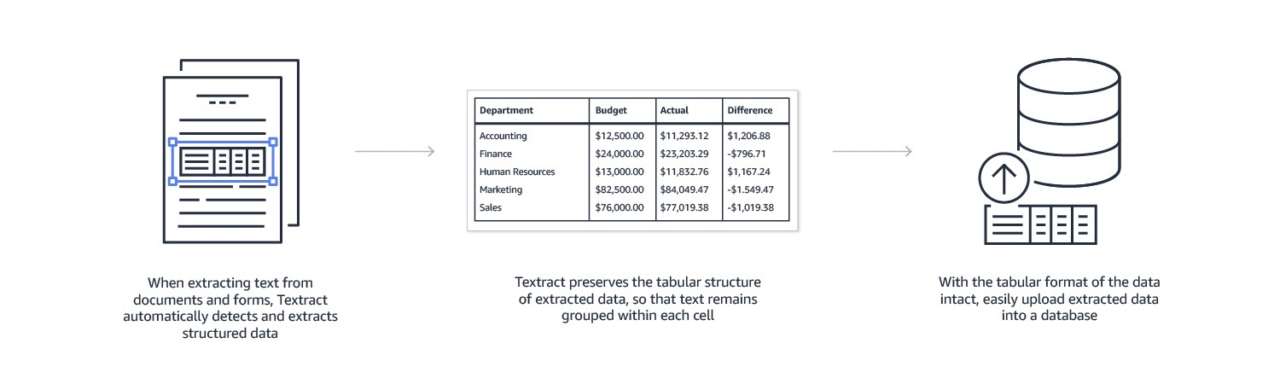 Amazon Textract prende i file scansionati memorizzati in un bucket Amazon S3, li legge e restituisce i dati sotto forma di testo JSON annotato con il numero di pagina, la sezione, le etichette dei moduli e i tipi di dati. Questi dati possono quindi essere utilizzati per una vasta gamma di applicazioni aziendali, come fogli di calcolo, database e sistemi gestionali.
Amazon Textract prende i file scansionati memorizzati in un bucket Amazon S3, li legge e restituisce i dati sotto forma di testo JSON annotato con il numero di pagina, la sezione, le etichette dei moduli e i tipi di dati. Questi dati possono quindi essere utilizzati per una vasta gamma di applicazioni aziendali, come fogli di calcolo, database e sistemi gestionali.
The Globe and Mail, MET Office, PwC, Healthfirst, UiPath, Teradact, Ripcord, Kablamo, Vidado, BluePrism e Alfresco sono alcuni tra i clienti e i partner di Amazon che utilizzano il servizio Textract.
Maggiori informazioni su Amazon Textract sono disponibili sul sito AWS, a questo link.









{kind=link}